LSH
Locality-Sensitive Hashing과 응용에 대해 알아봅니다.읽는데 7분 정도 걸려요.LSH
LSH는 비슷한 객체를 찾는 방식 중 하나로, 일반 해싱과 비슷하게 동작하지만, 큰 차이가 있습니다.
일반 해싱은 데이터가 조금만 달라져도 아웃풋이 완전히 달라지는 반면,
LSH는 해싱을 부분적으로 진행하기 때문에 조금만 달라지면 아웃풋도 조금만 달라지게 됩니다.
예시를 통해 알아봅시다.
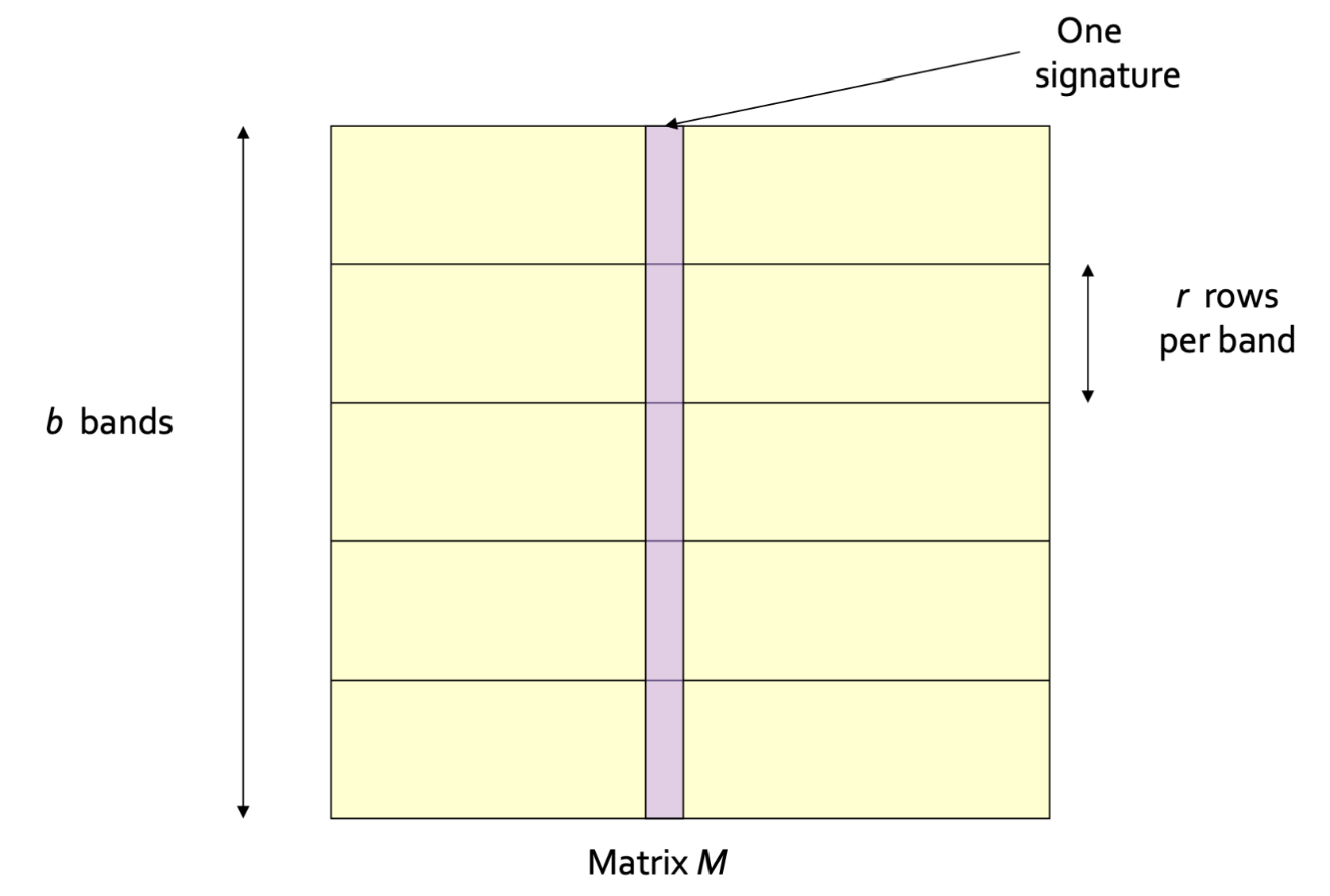
LSH는 해싱을 진행할 때, 전체 데이터를 해싱하는 것이 아닌, 전체 데이터를 b등분한 b개의 bands를 각각 해싱합니다.
해싱된 band는 그 아웃풋에 해당하는 bucket에 담기게 됩니다.
만약 두 문서가 비슷하다면 어떨까요?
비슷한 두 문서는 높은 확률로 시그니처가 동일한 band를 갖고 있을 것입니다.
즉, 비슷한 분서는 같은 bucket에 담기는 band를 공유하고 있을 것입니다.
물론, 다른 입력에 대해 같은 아웃풋이 해싱에는 존재할 수 있습니다.
따라서 가능한 많은 bucket를 확보하여 분류하는 것이 좋습니다.
또는 각 band 별로 다른 해시 테이블을 사용하여 다른 버킷에 할당될 수 있도록 하는 것도 방법입니다.
그런데 LSH가 얼마나 효율적인지도 알아봐야겠죠?
10만개의 문서가 각각 길이 100의 시그니처를 갖고있다고 가정해봅시다.
80% 비슷한 문서, 즉 시그니처가 80개 이상 일치하는 비슷한 pair를 찾고싶다면, 일반적인 방법으로는 아래와 같은 연산 횟수가 필요합니다.
즉 10만개의 문서을 일일이 비교하려면 약 50억 번의 비교 연산이 필요합니다.
하지만, LSH로 우선 비교 대상을 줄인다면?
LSH로 10만 번의 연산이 필요하고, 비교 대상이 100개로 줄어든다면 아래와 같은 연산 횟수가 필요합니다.
LSH를 사용하는 것 만으로 연산 횟수가 기하급수적으로 줄어든 것을 확인할 수 있었습니다.
하지만, 앞서 언급했 듯, 다른 band도 같은 bucket에 들어갈 확률이 있습니다.
그렇기에 LSH는 false negative가 발생할 확률도 있기 때문에, 같은 bucket에 들어간 candidate pair에 대해 실제로도 비슷한지 전 시그니처를 검사하는 과정을 거쳐 유사도를 판단하는 게 좋습니다.
(LSH는 전처리 과정일 뿐!)
Confidence
그렇다면, LSH의 신뢰도는 얼마나 될까요?
5int/band 단위로 길이 100의 시그니처를 20개의 bands로 분할하고, LSH를 적용한다고 가정해봅시다.
문서 , 가 80% 확률로 비슷할 때, 한 band가 같은 버킷에 들어갈 확률은 다음과 같습니다.
그렇다면, 20개의 모든 밴드가 다른 버킷의 들어갈 확률은 다음과 같아집니다.
즉, 문서 , 가 80% 확률로 비슷하다면 약 99.99965%의 확률로 최소한 하나의 bucket에 두 band가 들어갈 것입니다.
40% 확률로 비슷한 경우는 어떨까요?
즉, 40% 확률로 비슷하다면 약 18%의 확률로 최소한 하나의 bucket에 두 band가 들어갈 것입니다.
40%만 비슷해도 비슷하다고 판단해야 하는 시스템의 경우 88%의 케이스가 False positive가 되어버립니다.
그럼에도 불구하고 50억번 비교하는 것 보다는 나을 것입니다.
Analysis
위의 경우 80% 유사도를 검사할 때는 신뢰도가 매우 높았지만, 40%을 검사할 때는 신뢰도가 상당히 낮았습니다.
신뢰도는 b(bands)와 r(ints/band)의 값에 영향을 받는데, 각각의 파라미터가 어느정도일 때 유사도에 따른 신뢰도는 어떻게 나오는 걸까요?
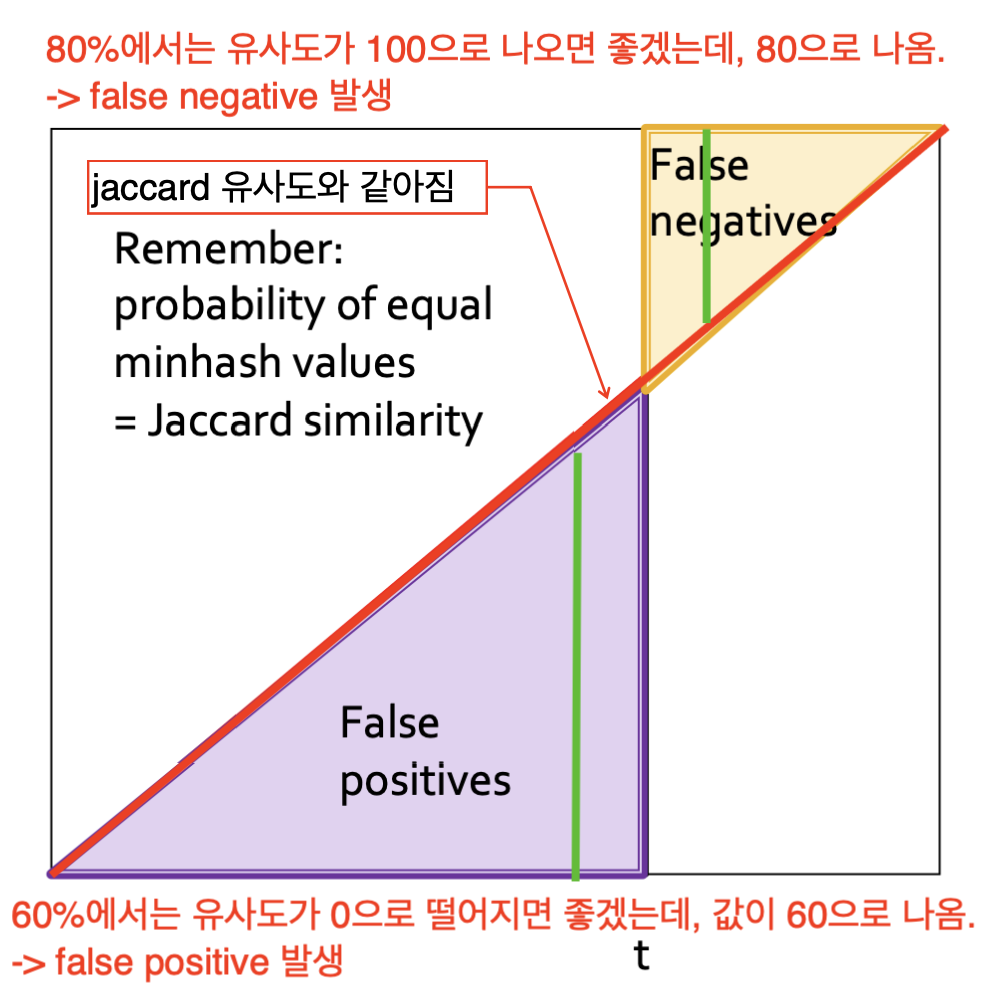
우선 band가 1개일 때의 신뢰도 입니다.
band가 1개라는 것은 그냥 데이터 전체를 해싱하는 것과 같습니다.
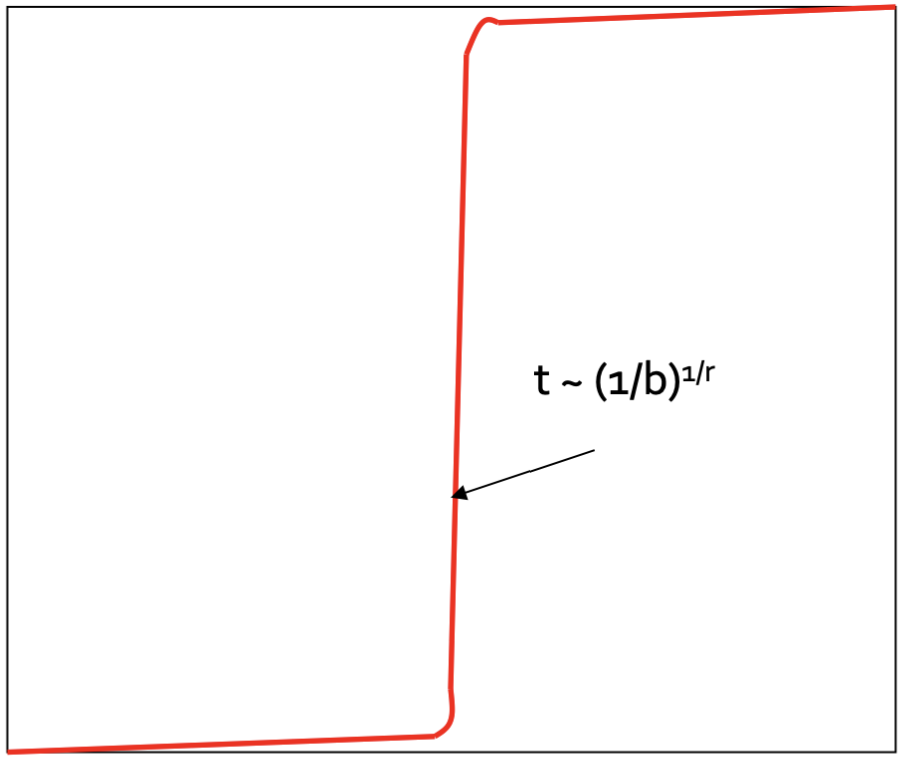
다음은 band가 b개이고, r ints/band 일 때의 일치율 s에 따른 신뢰도 입니다.
지점에서 신뢰도가 급격하게 증가하는 모습을 볼 수 있습니다.
b=20, r=5일 때 약 55% 일치율 지점에서 급격하게 증가합니다.