Spark 개념
MapReduce 모델의 확장판, Spark에 대해 알아봅니다.읽는데 10분 정도 걸려요.MapReduce 문제점
기존 MapReduce 모델의 문제점은 데이터 복제, Disk I/O 등의 오버헤드가 크다는 점이었다.
하지만, ranks를 2개(map, reduce)로 나누어 관리하여 한 반향으로 데이터를 흐르게 만들어
시스템이 다운될 경우 재시작의 효율성이 올라가는 점도 고려하여 구현되었다.
(단방향으로 흐르기에 처리 실패가 발생한 지점부터 다시 처리하면 됌)
그러나, rank가 2개라 모든 문제를 map-reduce 패턴으로 묘사하기가 쉽지 않다는 점도 있었다.
Spark
스파크는 오늘날 가장 많이 쓰이는 Data-Flow system으로 MapReduce에 비해 여러 부분에서 개선이 이루어졌다.
- rank를 2개로 제한하지 않음.
map, reduce 외의 tasks, ranks와 같은 여러 단계를 허용함. - Map, Reduce 외의 별도의 유용한 함수 제공.
- 바로 디스크에 중간 결과를 저장하지 않고, 메모리에 캐싱하기도 함.
적당한 크기의 중간 결과는 메모리에 캐싱하기에 속도로 보다 빠르다 - MapReduce와 마찬가지로 단방향으로 데이터가 흐르는 DAGs 형식을 따른다.
(Directed Acycle Graphs) - 여러 언어와 api를 제공하고, 오픈소스이며 호환성도 좋다.
vs. Hadoop MapReduce
Spark이 더 빠른대신 메모리 사용량도 더 많다.
Spark에서 제공하는 api가 더 많아 사용하기에 더 편하다.
둘 다 map-reduce 부분에서는 성능차이는 없다.
RDD
Resilient Distributed Dataset의 약어로 Spark에서는 큰 데이터를 RDD 라는 청크로 쪼개어 key-value 페어로 저장한다.
즉, RDD가 여러개의 클러스터에 분산 저장되는데, 가장 큰 특징은 RDD는 읽기 전용이라는 점이다.
그렇기에 파일로부터 RDD를 얻어오기도 하며, RDD로부터 새로운 RDD를 만드는 식으로 작업된다.
또한, RDD는 일반적으로 메모리에 캐싱되며, 필요에 따라 디스크에 저장하기도 한다.
DataFrame
RDD와는 다르게 데이터들이 테이블 형태로 저장되먀 column별로 이름도 있다.
DataSet
DF의 상위호환으로 타입 세이프, 객체지향 프로그래밍 인터페이스를 지원하며, 컴파일 타임에 에러도 잡아낼 수 있다.
Transformations
RDD에서 새로운 RDD로의 변환을 Transformations라고 하는데, map, filter, join, union, intersection, distinct와 같은 변환이 있다.
중요한 점은 이러한 변환은 Lazy evaluation 하게 동작한다는 점인데, 이게 무슨 말이냐면
뭔가를 지시를 해도 실제로 수행을 하지 않는다는 뜻이다.
지시를 하면 지시 사항을 기록하다가 사용자가 실제로 값을 요청시 기록된 요청을 최적화 알고리즘을 적용하여 한 번에 실행하기 때문에 효율적으로 동작하게 된다.
Actions
Lazy evaluation 중 실제로 동작을 수행하게 하는 명령이다.
count, collect, reduce, save 와 같은 명령이 있다.
Task Scheduler (General DAGs)
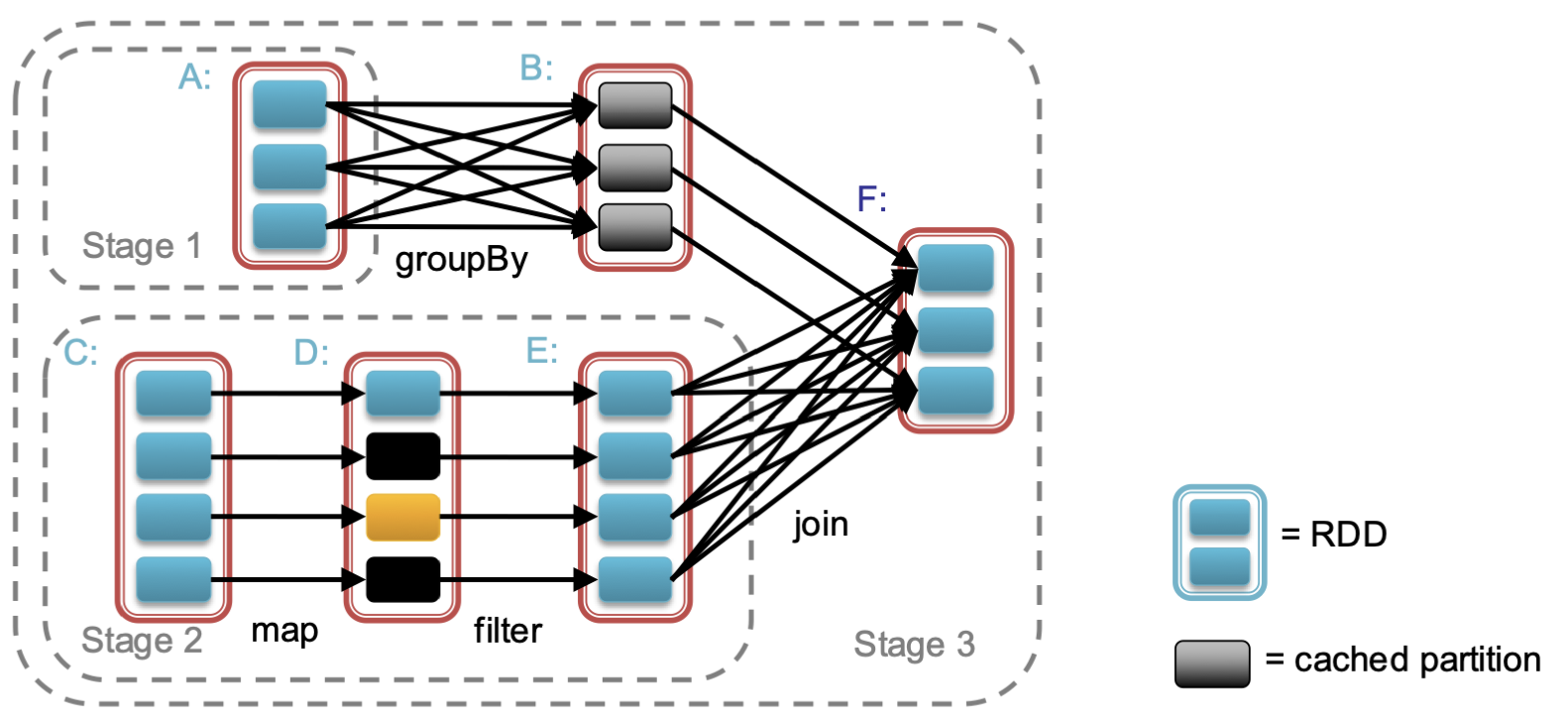
Spark 스케쥴러는 스마트하게 동작하는데 그 특징은 다음과 같다.
- 파이프라인 함수를 제공한다.
Stage 1, Stage 2와 같이 여러 단계를 추상화하여 하나의 단계로 취급해 성능을 최적화 한다. - 감당 가능한 크기의 데이터는 캐싱한다.
데이터를 캐싱하여 재사용성을 높이고, 속도도 빠르게 한다. - key값 분포상태를 파악하여 불필요한 shuffle을 피한다.
일례로 A → B로 넘어가며 키 값이 정렬되었으니, B → F로 넘어갈때는 불필요한 셔플을 하지 않음.
methods (real-code)
Finding Similar Item까지 본 뒤에 코드를 보는 것이 더 좋습니다.
(Spark) DataFrame
-
printSchema()
해당 데이터프레임의 스키마를 보여줍니다. -
take(N)
N개의 행을 보여줍니다. -
show(n=N, truncate=boolean)
N개의 행을 표 형태로 정리하여 보여줍니다.
truncate=False시 ...으로 요약되지 않은 전체 문자열을 출력합니다. -
select(columnName[])
columnName에 해당하는 column들만 남긴 spark dataframe 객체를 반환합니다. -
selectExpr(sqlSelect[])
sql select문에서 사용할 수 있는 문법을 이용하여 해당 column을 가져온 뒤 dataframe 객체로 반환합니다. -
sort(columnName, ascending=boolean)
columnName을 기준으로 오름차순 정렬합니다.
ascending=False시 내림차순으로 정렬합니다. -
join(dataframe, this.column == dataframe.column)
본인(this) dataframe과 인자로 넣은(dataframe) dataframe의 공통 column을 기준으로 natural join을 수행 후 dataframe 객체를 반환합니다.
단, 일반 sql과 다르게 공통 column이 하나만 표시되는게 아닌 중복되서 표시됩니다. -
toPandas()
데이터가 pandas로 옮길 수 있을 만큼 작다면, spark dataframe에서 pandas dataframe으로 변환합니다. -
groupBy(columnName[])
배열에 들어있는 모든 columnName을 기준으로 그루핑한 후 GroupedData 객체를 반환합니다. -
rdd
spark dataframe에서 RDD 인스턴스를 생성합니다.
(spark) GroupedData
-
count()
각 그룹의 행의 개수를 카운트하여 count column을 만들고 dataframe 객체를 반환합니다. -
agg(column)
column에 대해 집계함수를 수행합니다.
아래와 같이 응용하여 사용하면 item을 직렬화할 수 있습니다.
alias를 이용해 column의 이름을 변경할 수 있습니다..pydf = orders_joined.groupBy('order_id').agg(collect_set('product_name').alias('items')) df.show()order_id items 1 [Bag of Organic B... ] 96 [Roasted Turkey, ... ] 112 [Umcka Elderberry... ]
RDD (PipelinedRDD)
-
collect()
RDD를 출력합니다. -
map(function(row))
RDD에 대해 function를 적용합니다.
파라미터로 RDD의 row가 전달됩니다..pyall_locations = jun_29_operations.rdd.map(lambda row: (row.TakeoffLocation, 1)) all_locations.take(3)적용 후 PipelinedRDD 객체를 반환합니다.
[('TAKHLI', 1), ('DANANG', 1), ('CONSTELLATION', 1)]
-
flatMap(function)
map과 동일한 기능을 수행합니다.
단, 결과가 1차원 배열만을 반환합니다..pyRDDs1 = RDDs1.flatMap(lambda line: line.split(' ')) -
reduceByKey(function(number, number))
PipelinedRDD에 대해 function을 적용합니다.
파라미터로 2개의 key-value pair에 대해 value가 전달됩니다..pylocations_counts_rdd = all_locations.reduceByKey(lambda a, b: a+b).sortBy(lambda r: -r[1]) locations_counts_rdd.take(3)적용 후 PipelinedRDD 객체를 반환합니다.
[('CONSTELLATION', 87), ('TAKHLI', 56), ('KORAT', 55)]
-
sortByKey(ascending=boolean)
RDD key-value pair에 대해 key값을 기준으로 정렬합니다. -
filter(function)
function이 true를 반환하는 값만 통과시켜 RDD객체를 반환합니다.
spark instance
-
sql(queryString)
sql문법을 queryString를 실행한 후 spark dataframe 객체를 반환합니다. -
createDataFrame(RDD)
RDD를 spark dataframe 인스턴스로 변환합니다.
단, 인스턴스의 Row에 따라 Column의 이름이 결정됩니다.예로 들어 reduceByKey 이후 바로 createDataFrame 생성시 Row의 이름이 작성되지 않아 Column명이 _1, _2와 같은 식으로 초기화됩니다.
따라서 아래의 코드로 이름을 지정하는 것이 시각화에 도움이 됩니다.
.pylocations_counts_with_schema = locations_counts_rdd.map(lambda r: Row(TakeoffLocation=r[0], MissionsCount=r[1])) locations_counts = spark.createDataFrame(locations_counts_with_schema) locations_counts.show() -
sparkContext.textFile(path)
path에 해당하는 파일을 읽은 뒤 RDD 인스턴스를 반환합니다.
FPGrowth
-
FPGrowth(itemsCol=columnName, minSupport=number, minConfidence=number)
dataframe의 columnName에 대해 연관규칙을 생성하는 FPGrowth 인스턴스를 생성합니다.
이 때 minSupport, minConfidence를 설정해야 합니다. -
fit(dataframe)
생성된 FPGrowth 인스턴스에 대해 dataframe을 적용하여 FPGrowthModel을 만듭니다. -
freqItemsets, associationRules
생성된 FPGrowthModel에 대해빈발 항목 집합과연관 규칙을 생성합니다..py# grouping with order_id df = orders_joined.groupBy('order_id').agg(collect_set('product_name').alias('items')) # change to spark dataframe df = spark.createDataFrame(df.toPandas(), ['id', 'items']) # analysis using FP-Growth from pyspark.ml.fpm import FPGrowth fpGrowth = FPGrowth(itemsCol='items', minSupport=0.01, minConfidence=0.5) model = fpGrowth.fit(df) num_freqItemsets1 = model.freqItemsets.count() num_associationRules1 = model.associationRules.count()