분산 파일관리 시스템
분산 파일관리 시스템에 관련한 기초 지식을 배웁니다.읽는데 11분 정도 걸려요.분산 파일관리 시스템
방대한 데이터 보관, 또는 백업을 위해 데이터를 분산 저장하는 경우 여러대의 컴퓨터를 연결하여 하나처럼 동작하도록 구성해야 한다.
하지만, 실시간으로 데이터를 처리해야 하는 부분에 대해서는 데이터를 복사하여 네트워크 전송을 통해 처리하는 방식은 네트워크 속도가 상대적으로 매우 느리기 때문에 문제가 있다.
이런 경우에는 데이터를 옮기는 것이 아닌, 필요한 데이터를 보관하는 컴퓨터에게 연산 작업을 맡기고, 동기화는 주기적으로 하는 방식을 사용하는 것이 좋다.
이렇게 데이터를 분산하여 저장하는 시스템을 분산 파일관리 시스템이라 불리고, Spark, MapReduce와 같은 시스템이 이런 방식을 사용한다.
하지만, 이런 파일관리 시스템은 1개의 머신만을 사용하는 시스템에 비해 속도가 느리기 때문에 아래의 조건을 만족하는 경우에만 사용하는 것이 바람직하다.
- 데이터 양이 매우 많은 경우
- 데이터의 수정은 왠만하면 일어나지 않는 경우
- 읽고 이어쓰기가 빈번하게 일어나는 경우
Chunk servers
16~64MB 정도의 파일을 하나의 Chunk로 묶어 관리하는데, 이런 청크를 2, 3배 중복으로 다른 물리적 공간에 저장하는 식으로 분산 관리를 하게 되는데,
이런 다른 물리적 공간을 Chunk server 라고 부른다.
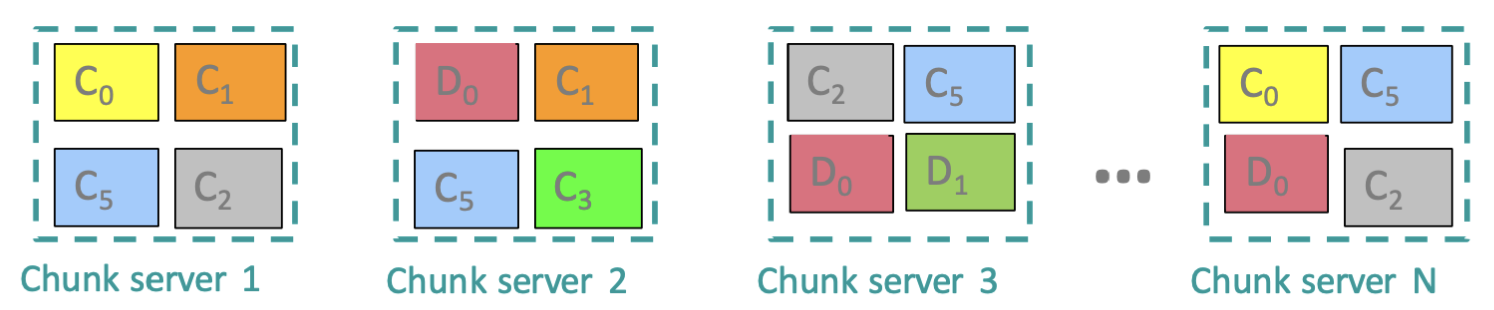
따라서 여러 청크서버에 동일한 청크가 분산 저장되어 있기 때문에 하나의 청크서버가 다운되더라도 데이터는 온전히 남는다.
또한, 위에서 언급했 듯, 데이터를 움직이는 것이 아닌 연산을 일임한다고 했는데,
서버의 과부화 방지를 위해 각 청크서버가 특정 청크에 필요한 연산을 전담하여 수행하고 결과를 반환한다.
Master node
파일이 저장된 위치인 메타데이터를 저장한 서버이다.
따라서 파일 엑세스 요청이 들어오면, 일단 모든 요청은 마스터 노드로 향하여 요청한 파일이 어느 청크서버에 있는지 알아낸다.
이후 그 요청에 대한 응답은 청크서버로 직접 엑세스되어 청크서버에서 요청이 처리되게 된다.
여기서 드는 의문점은 왜 마스터 노드가 직접 데이터를 전달하지 않는가이다.
그 이유는 마스터 노드에 엑세스가 제일 많은데 데이터까지 전달하게 되면 과부화가 걸리기 때문에 그렇다.
MapReduce
초창기 분산 컴퓨팅 프로그래밍 모델이다.
이 기술의 구현체로 Hadoop, Spark, Flink 등이 있는데, 이 모델의 동작 과정을 살펴보자.
overview
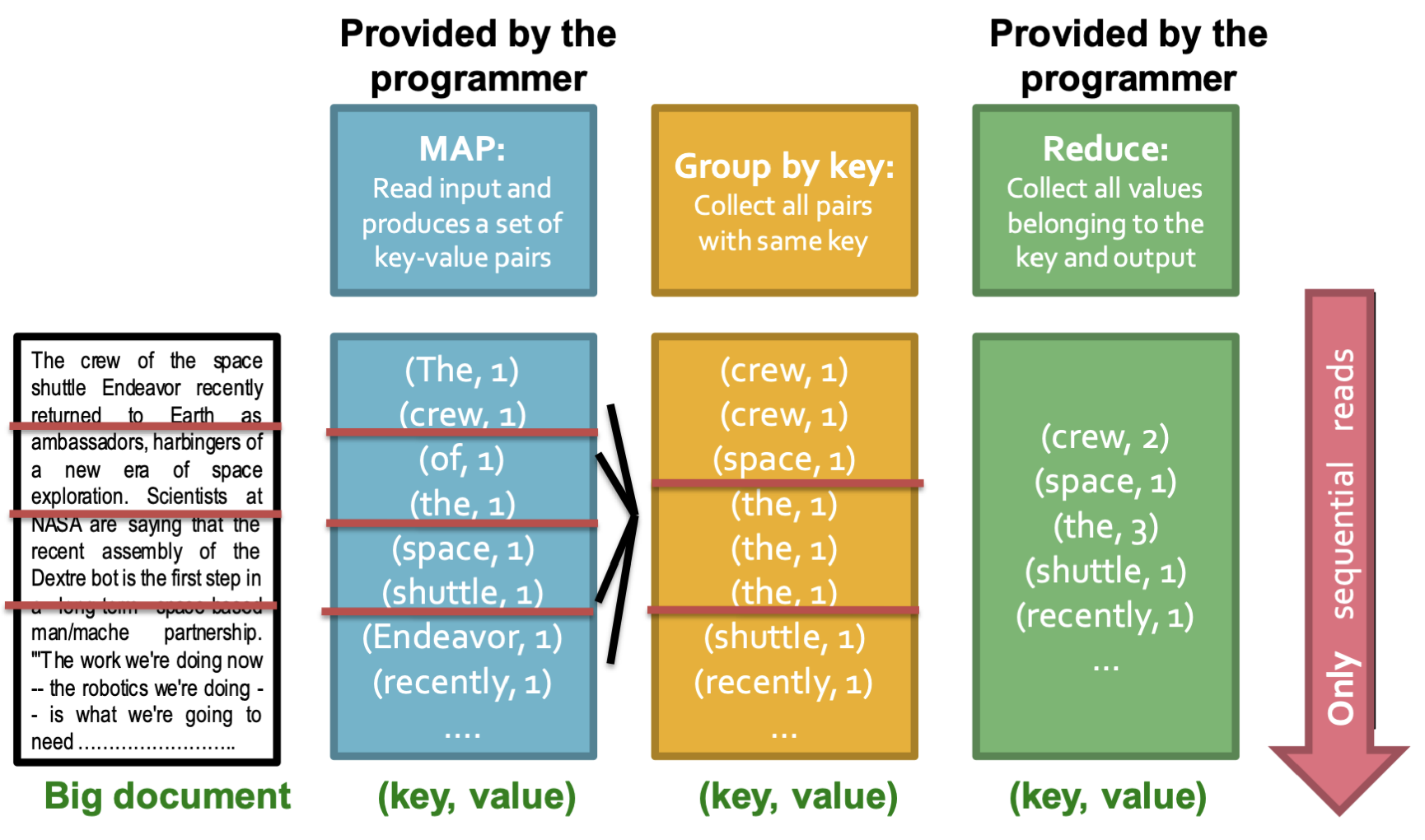
Map, Group by Key(보통 자동으로 일어남), Reduce의 3단계로 이루어지는데, 각 단계에서 어떻게 일이 처리되는지 알아보자.
참고로 Map, Reduce의 과정은 하나의 머신에서 일어나는 것이 아닌, 다중 머신에서 병렬적으로 일어난다는 점을 기억하자.
Map
우선 개발자가 Map 함수를 작성한다.
Map 함수는 읽은 데이터를 처리하기 위해 key-value pair로 변환하는 작업을 수행하게 된다.
하지만 MapReduce에서 사용 가능한 규격으로 데이터를 처리해야 하는데 이 과정이 좀 까다로울 수 있다.
추가로 이 이후에 생성된 key값을 이용해서 해싱같은 방식을 이용해 생성된 페어를 Reduce를 수행할 컴퓨터로 보내게 된다.
Group by Key
Map으로 얻어진 pair을 key값을 중심으로 정렬하고, 중복된 key들에 대해 value 들을 배열로 묶어주는 일을 처리한다.
대부분의 시스템에서 이 과정은 자동으로 일어나기 때문에 개발자가 개입할 부분이 상대적으로 적다.
하지만 성능적으로 이 단계에서 병목현상이 발생할 수 있다.
Map, Reduce는 파일이나 청크를 한 번만 탐색하면 끝나지만(),
Group by Key는 정렬 및 그루핑을 해야하기 때문에 상대적으로 느리기 때문이다().
Reduce
개발자가 개발한 Reduce 함수를 이용해 배열로 되어있는 values들을 하나로 합쳐준다.
이 과정이 종료되면 유니크한 key-value pairs가 생성될 것이다.
Dealing with Failures
Map worker가 다운된 경우에는 일이 진행 중이든 완료되었든 간에 무조건 다른 worker에게 일을 처음부터 재시작하게 한다.
왜냐하면 일이 완료된 경우 그 결과를 시간 비용의 문제 때문에 로컬 디스크에 데이터를 저장하기 때문이다.
반면에 Reduce worker가 다운된 경우에는 일이 진행 중인 경우에만 다른 worker에게 일을 처음부터 재시작하도록 한다.
Reduce일이 완료된 경우, 그 결과는 중요한 데이터이니 분산 저장하기 때문에 완료된 경우에 다운되어도 재시작할 필요가 없는 것이다.
Cost Measure
MapReduce 내부적으로 사용되는 알고리즘의 비용을 측정해보자.
- Communication cost
모든 프로세스의 I/O bytes
(아래 항목을 모두 더하면 됌)
- 입력 파일 사이즈
- 2 Map process → Reduce process 로 이동한 파일 사이즈 (2를 곱한 이유는 Map, Reduce 2개이기 때문)
- Reduce process에서 나온 출력 사이즈의 합
- Elapsed communication cost
Communication cost 중 가장 큰(peak) 비용 (정확히는 파일 사이즈가 가장 큰 입력 파일 기준)
→ 이 비용이 작을수록 병렬(분산)화가 잘 되었다는 뜻이다. - (Elapsed) Computation cost
1, 2와 동일, 단, 기준이 byte 단위가 아닌 I/O 시간 단위 기준임.
대부분의 클라우드 서비스는 Communication cost 기준으로 비용이 청구됌.
(Elapsed는 기준은 아님)
Problems Suited for MapReduce
Spark과 같은 라이브러리 말고 MapReduce만 사용하기에도 충분한 문제들을 알아보자.
보통 데이터 순차탐색 문제나, 비 실시간으로 처리되어도 상관없는 여유로운 작업에 적합하다.
Host size
url로 부터 host를 추출하고, 해당 호스트에서 제공하는 많고 거대한 데이터의 총 크기(용량)을 알고싶을 때 사용할 수 있다.
(host1, size1)
(host2, size2)
...
Language Model
언어 모델 개발시에도 이용할 수 있다.
5개의 단어 뭉치가 문서에서 얼마나 등장하는지
(5-word seq, count)
이런 경우도 map, reduce로 간단하게 만들 수 있다.
join
join 연산도 MapReduce로 할 수 있다.
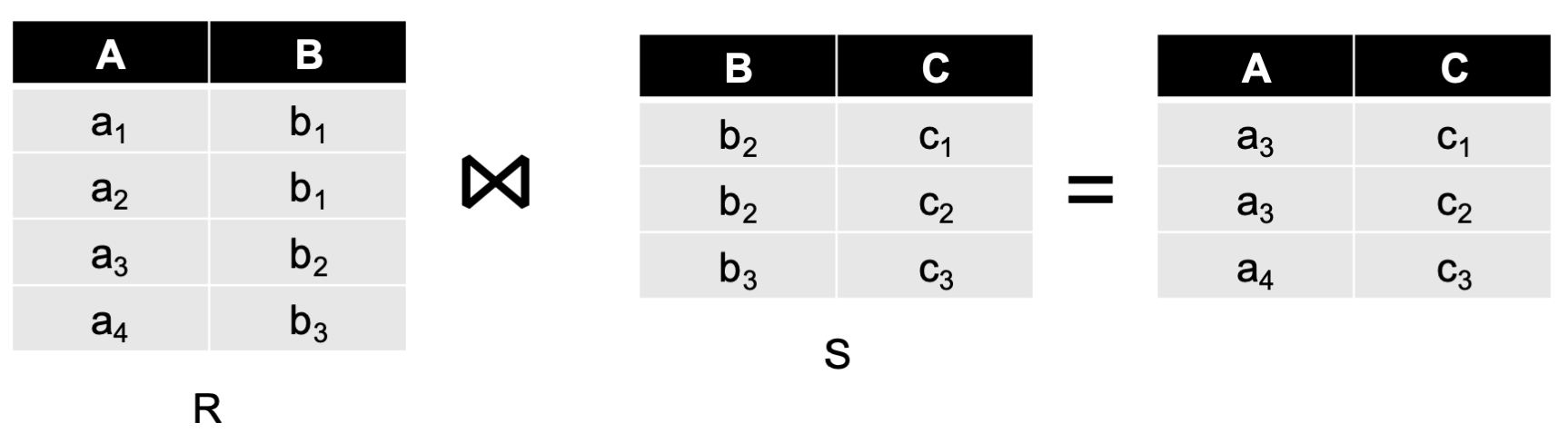
를 natural join한다로 해보자.
Map
- join에 사용될 column을 key로 사용하는 key-value 페어로 만든다.
(, (, R))
(, (, R))
(, (, R))
(, (, R))
(, (, S))
(, (, S))
(, (, S))
- 키값을 해싱한 후 Reduce 프로세스로 보낸다.
Reduce
- Reduce를 진행한다.
(, [(, R), (, R)])
(, [(, R), (, S), (, S)])
(, [(, R), (, S)])
- values에 R-S로 되어있는 value들만 묶어서 (a,b,c)로 출력한다.
(R-R, S-S를 제외하기 위해서 value pair에 R, S를 포함시킨 것이다)(, , )
(, , )
(, , )
Not Suited
적합하지 않은 문제상황은 뭐가 있을까?
graph 탐색이나, ML에서의 비 순차탐색 하는 경우에는 적합치 않다.