자연어 처리
자연어 처리의 과정에 대해 간략히 알아봅니다.읽는데 6분 정도 걸려요.분석 단계

형태소 분석
입력된 문자열을 분석하여 형태소 단위로 분석합니다.
형태소 분석은 다음과 같은 목적 활용될 수 있습니다.
- 맞춤법, 철자 교정
- 단어의 품사 분석
- 단어의 의미 추정
- 검색엔진 색인 구성
형태소를 분석하고 나서는 품사를 태깅합니다.
태깅을 할 때는 문장의 구성 원리 등을 이용한 규칙 기반 태깅 방법과, 기계학습 기반 태깅이나, 통계적 기계학습 알고리즘을 사용할 수 있습니다.
이후에는 개체명을 인식합니다.
정보를 검색하거나, 질의응답에서 중요한 역할을 하는 고유명사와 같은 개체명을 인식하는 겁니다.
인명, 지명, 시간, 날짜, 화폐 등이 이에 해당합니다.
개체명을 인식할 때는 사전을 사용하거나, 규칙을 만들거나, 기계학습 기반의 분류기를 사용합니다.
구문 분석
구문에 따라 주어진 문장에서 단어들의 역할을 파악하여 문장을 계층적인 트리 구조로 변환하는 작업입니다.
이 역시 규칙 기반 구문 분석방법과 기계학습 기반 구문 분석방법이 있습니다.
하지만, 구문 분석시에는 아래와 같은 문제점이 있을 수 있습니다.
- 구조적 중의성
하나의 문장이 다수의 구조로 해석될 수 있음. - 어휘적 중의성
하나의 단어가 여러 품사로 사용될 때, 다수의 구조로 해석될 수 있음.
규칙 기반 구분 분석에서는 파싱 방식을 자주 사용하는데, 파싱 방식에는 아래와 같은 방식이 있습니다.
- 확장 전이망 기반 파싱
- 차트 파싱 (CKY 파싱 알고리즘)
기계학습 기반 구문 분석에서는 아래와 같은 모델이 사용됩니다.
- SVM
- 조건부 랜덤 필드(CRF) 모델
- 딥러닝 신경망
의미 분석
형태소, 구분 분석 결과를 해석하여 문장이 가진 의미를 파악합니다.
이를 위해 담화가 이루어지는 상황에 대한 world model과 상식에 대한 지식이 필요합니다.
이를 위해 단어를 수치화 해야 하는데, ont-hot vector 또는 Word2Vec(word embedding)을 사용합니다.
두 방식 모두 단어를 좌표상에 하나의 위치벡터로 수치화 합니다.
-
one-hot vector
단어 위치에만 1, 나머지는 0으로 설정된 벡터입니다.
학습에는 편리하지만, 이 방식은 단어간의 유사도를 계산하기가 어렵습니다. -
Word2Vec
단어의 의미를 충분히 잘 나타내도록 단어를 공간상의 실수 벡터로 표현합니다.
유사한 의미의 단어는 좌표공간 상에서 근처에 위치하게 되기 때문에 유사도를 판단할 때 유용합니다.
이렇게 단어를 벡터화(수치화) 하고나면, 단어를 유의미하게 배치하기 위한 모델을 구성해야 합니다.
one-hot vector로 수치화된 단어는 아래와 같은 모델에서 사용됩니다.
-
CBOW
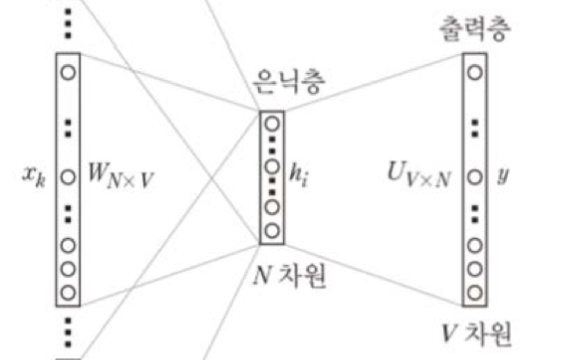
Continuous Bag-of-Words 모델은 V차원의 one-hot 벡터로 표현된 단어를 N차원의 실수 벡터로 바꾸는 역할을 수행합니다.
입력에 주변 단어들이 주어질 때, 출력에서 해당 단어가 나타날 확률이 높아지도록 학습합니다.
e.g. 빈칸 채우기 -
Skip-gram
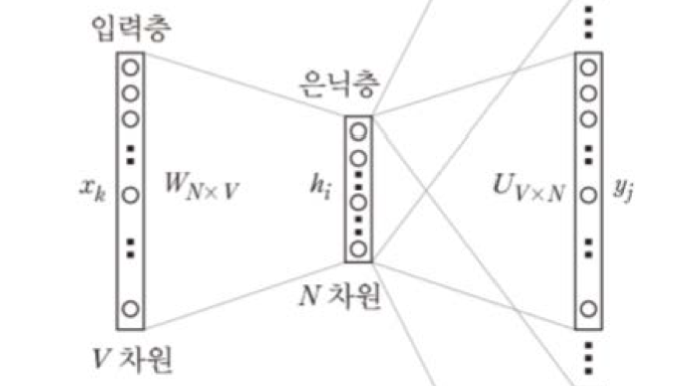
CBOW 모델과 대칭적인 구조를 갖습니다.
입력에 학습 대상이 되는 단어가 주어질 때, 출력에서 해당 단어의 주위 단어들이 나타날 확률이 높아지도록 학습합니다.
e.g. 문장 생성
Word2Vec로 수치화된 단어는 아래와 같은 분야에서 사용됩니다.
- 유의어, 어근 비교, 시제 등 한 정보 추출 또는 분석
- 품사 태깅, 의미 분석, 관계 추출, 단위 의미 식별 등
- 기계 번역, 영상 주석달기 등