Feature Detection and Matching
영상에서 특징점을 찾고 매칭하는 법을 알아봅니다.읽는데 9분 정도 걸려요.영상에서 특징점을 찾고 이를 매칭하는 방식에 대한 기본적인 아이디어는 다음과 같습니다.
- 흥미로운 포인트를 찾는다.
- 흥미로운 포인트를 설명하기 위한 벡터를 추출한다.
- 흥미로운 포인트를 정보 벡터를 이용해서 매칭한다.
이번 포스트에선 그 흥미로운 포인트를 찾는 방식(아이디어)와 정보 벡터를 구하는 방식을 알아보겠습니다.
Feature Point
특징점을 찾을 때 중요한 요소가 있습니다.
-
같은 특징은 다수의 영상에서 반복적으로 발견되어야 한다.
영상A와 영상B의 특징점이 다르게 추출되면 매칭이 성립되지 않기 때문입니다.
또한, 영상의 이동, 회전, 스케일링, 시점에 따른 왜곡, 빛의 변화, 노이즈가 있어도 동일한 특징점을 찾도록 하는게 좋습니다. -
특징점은 구분되는 설명(description)이 있어야 한다. (위의 벡터)
-
정말 좋은 특징점 일부만 추출해야 하고, 찾는 과정이 효율적이어야 한다.
-
특징점이 가능한 작은 영역에서만 존재해야 한다.
영상A에서 발견된 특징점(예로 얼굴을 구분하는 특징점들)이 영상B에서는 발견되지 않을 수 있기에 넓게잡지 않고 좁게 잡는것이 좋습니다.
이를 염두에 둔 특징점을 찾는 알고리즘에 대해 알아보겠습니다.
Harris Corner
Harris Corner 방식은 꼭짓점을 특징점으로서 찾는 방법입니다.
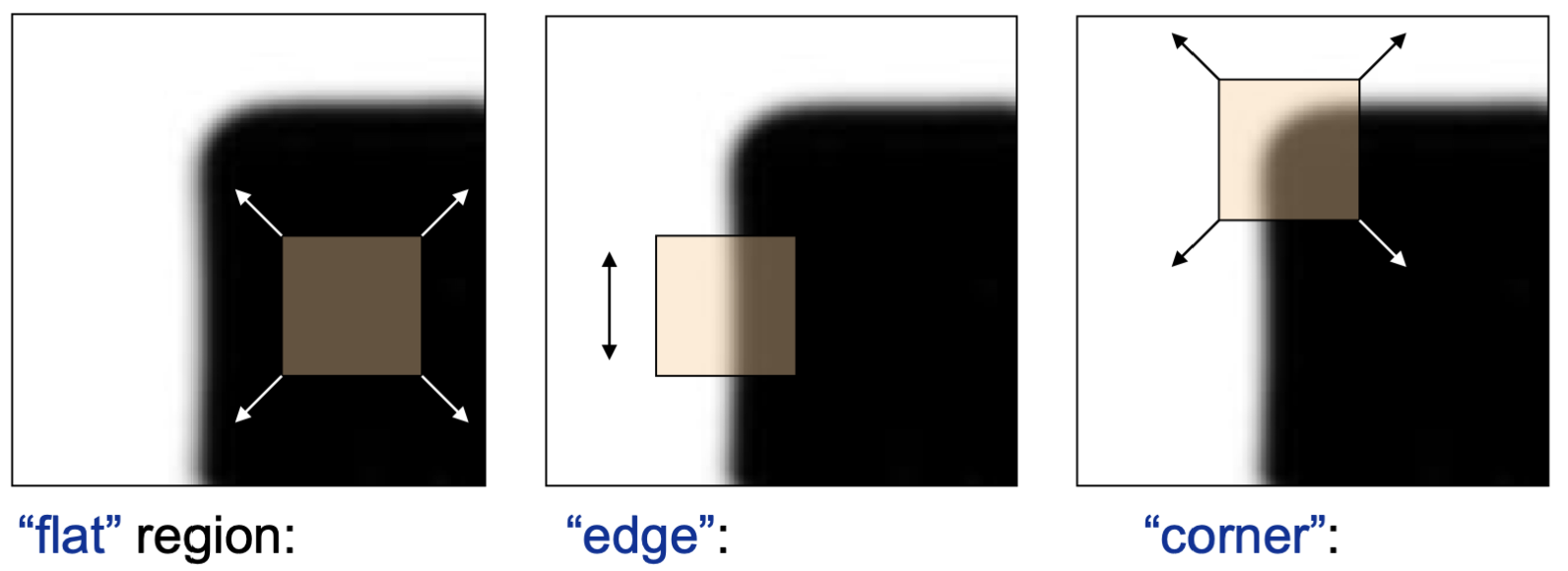
꼭짓점임을 알 수 있는 방법은 영상에서의 특정 방향에 대한 변화량을 측정하면 됩니다.
꼭짓점도, 모서리도 아닌 평탄한 부분에서의 x, y 축에 대한 변화량은 작거나 0에 가깝습니다.
반면에 모서리에 해당하는 부분은 x 또는 y 축 둘 중 하나에 대한 변화량만 큽니다.
이것과 대조되게 꼭짓점에 해장하는 부분은 x, y 모든 축에대한 변화량이 클 것입니다.
변화량을 측정하는 함수식은 아래와 같습니다.
여기서 W는 탐색하는 윈도우 함수이고, I는 해당 좌표의 에너지 레벨입니다.
이 때, 는 W가 이동하는 방향 벡터입니다.
즉, 가 90 라면 이상적인 결과가 나올 것입니다.
위 식을 테일러 급수로 근사하면 아래와 같은 식이 도출됩니다.
여기서 M은 아래와 같습니다.
여기서 , 는 각각 x, y축 방향으로의 gradient 크기를 의미합니다.
즉, , 의 크기 비교를 통해 Window가 가리키는 부분을 구분할 수 있습니다.
| flat | edge | corner |
|---|---|---|
| , : small | , : large |
그렇다면, 얼마나 커야 corner로 판단할 수 있을까요?
답은 설계하기 나름입니다.
하지만 나름 설계하는 기준은 있습니다.
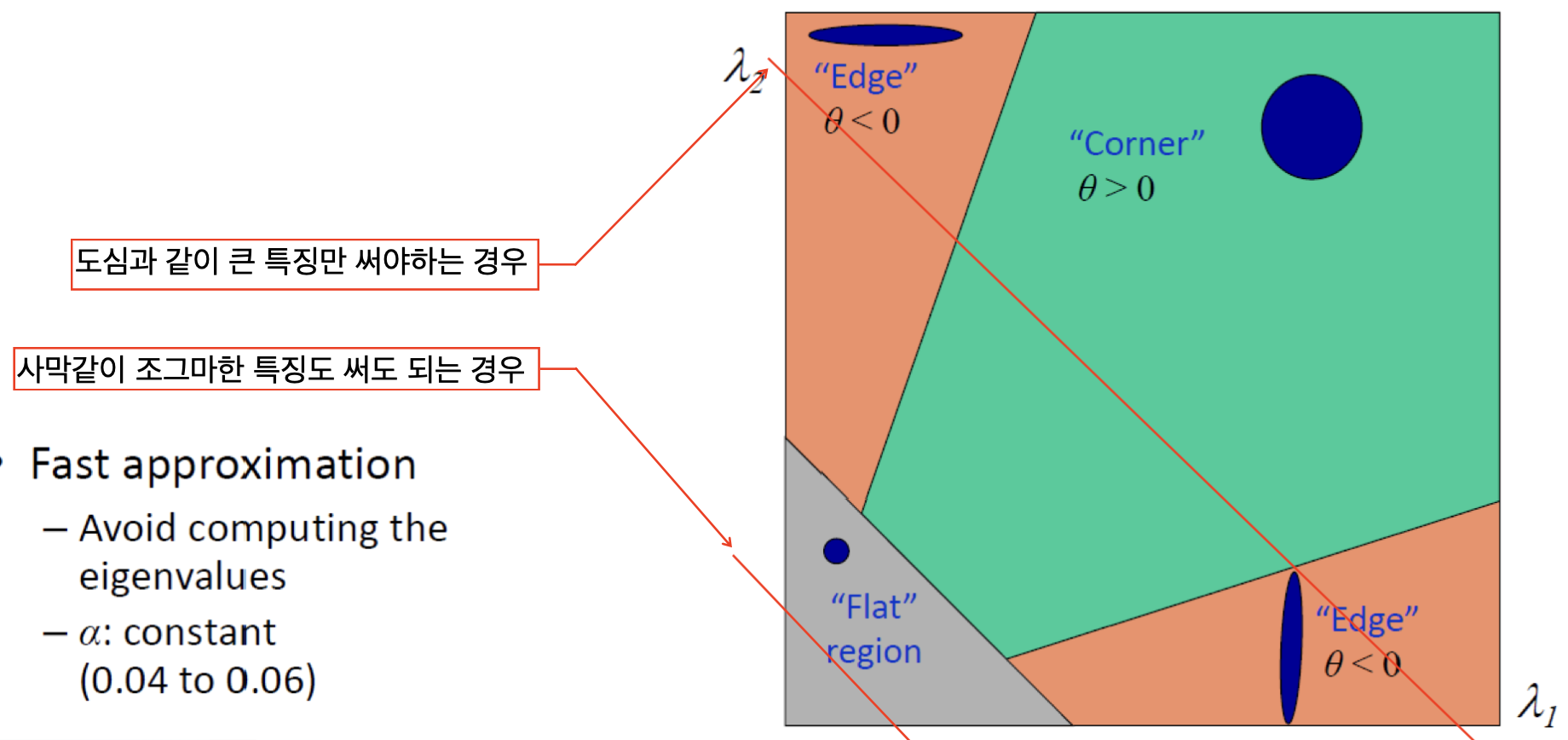
edge-corner는 아래와 같은 기준으로 판단할 수 있습니다.
즉, 도심같이 복잡해서 아주 큰 특징들만 검출할 필요가 있는 경우에는 를 크게 두어 크다고 판단하는 threshold를 높입니다. (corner영역을 줄임)
반대로, 사막과 같이 미세한 특징도 검출할 필요가 있는 경우에는 를 작게 두어 크다고 판단하는 threshold를 낮춥니다. (corner영역을 늘림)
한마디로 가 커질수록 특징점의 개수가 줄어듧니다.
flat-corner는 의 threshold 크기로 판단합니다.
한마디로 threshold가 커질수록 특징점의 개수가 줄어듧니다.
마지막으로 Harris corner(이하 HC)의 특징을 알아봅시다.
HC는 rotation, transition invariant 합니다.
즉, 영상을 회전시키거나 평행이동 시켜도 동일한 특징점을 찾아낼 수 있습니다.
하지만, scale invariant 하지는 않습니다.
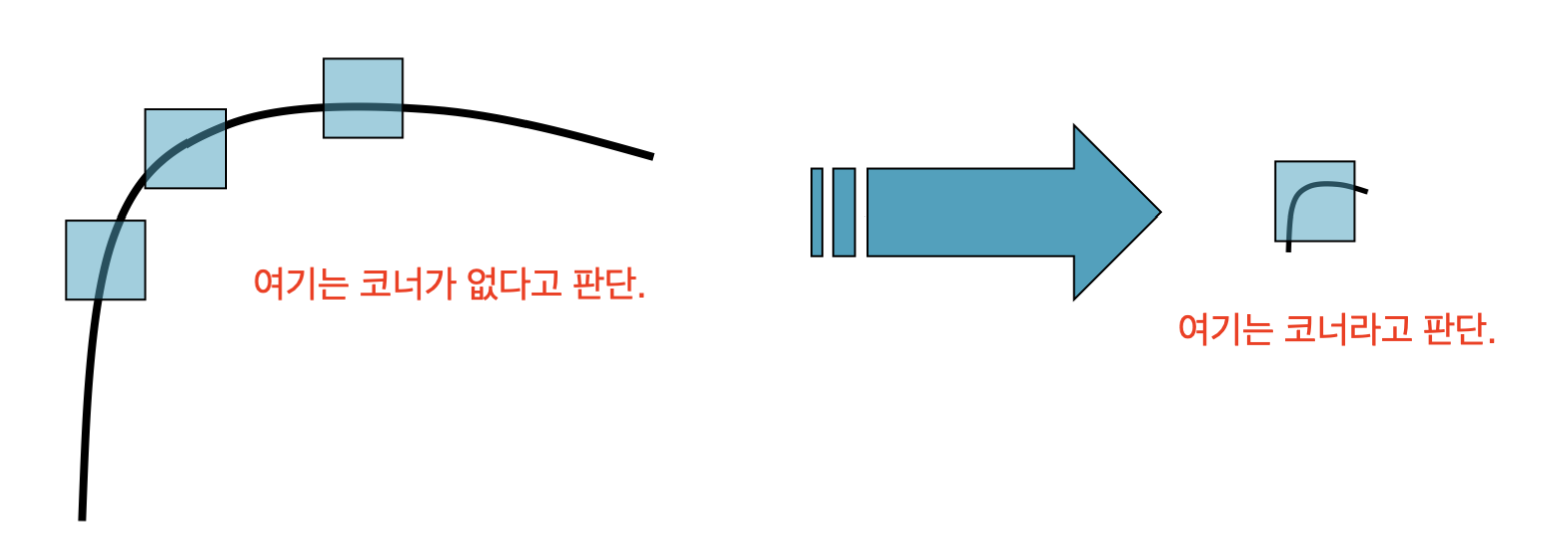
Scale Invariant Keypoint Detection
HC의 개선판으로 Window의 크기(patch size)도 찾아내어 scale invariant하게 특징점을 찾는 방법입니다.

위 영상은 Window 사이즈에 따른 특정 지점에서의 코너성을 함수로 표현한 것입니다.
그렇가면, 좋은 함수란 무엇을까요?

좋은 함수는 코너성이 최고로 나타나는 지점이 유일하게 결정되는 함수가 좋은 함수라고 판단합니다.
그렇다면 좋은 함수의 예시는 무엇이 있을까요?
Blob detection in 2D
2D 가우시안의 라플라시안으로, 특정 크기의 원형 영상에만 반응하는 필터입니다.
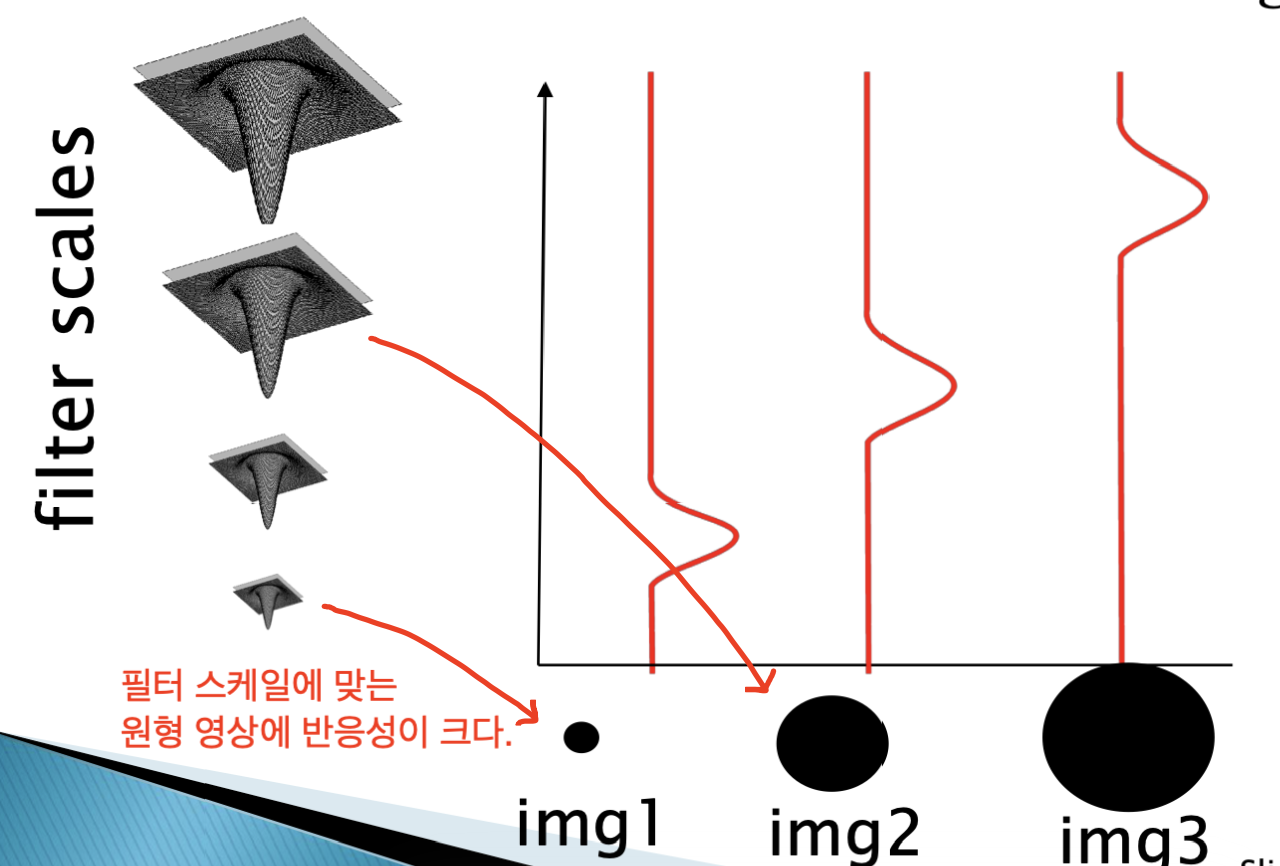
어떤식으로 반응하는지는 아래의 영상을 보며 이해해봅시다.

여기서 중요한 2가지 특징이 있습니다.
- 필터 크기에 맞는 원형 영상에 대해서만 반응을 한다.
- scale invariant 하게 반응한다.
즉, 특정 픽셀에서 반응값이 클 때의 값을 참고해서 Window 사이즈를 결정하면 Scale Invariant Keypoint Detection 를 구현할 수 있습니다.
참고로 위 영상은 해바라기라서 잘 되는 것이 아닌가? 원형 영상이 없으면 못 감지하는게 아닌가 하실 수 있겠습니다.
하지만, 극단적으로 원형이 아닌 영상이 아니고서야 여러 에 해당하는 Blob 필터가 동시에 반응하는 형식으로 잘 반응합니다.
(예시 영상이 있지만, 혐오스러울 수 있기에 올리진 않겠습니다)
SIFT Descriptor
지금까지 특징점을 찾는 방법을 알아보았다면, 이제는 특징점을 설명하는 방법을 알아봅시다.
Scale Invariant Feature Transform Descriptor는 픽셀별로 그레디언트(방향)을 구하고, 이를 히스토그램으로 정리한 뒤 벡터로 관리하여 정보를 담는 방식입니다.
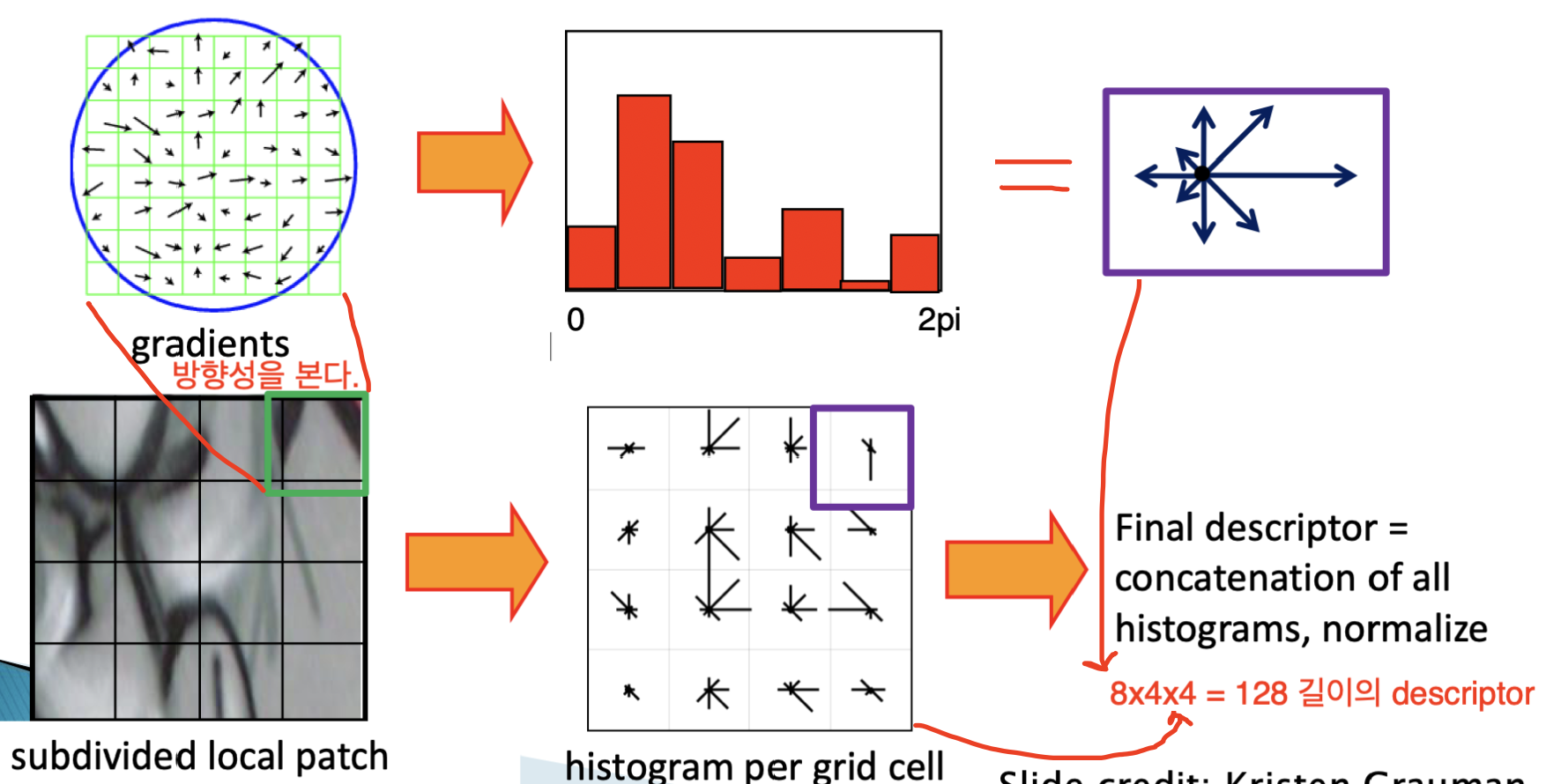
예로 들어 특징점 주변의 16셀에 대한 방향을 8개의 벡터로 표현한다면, 각 특징점마다 16*8 = 128길이의 Descriptor가 생성될 것입니다.
이 특징은 scale, rotation invariant 하기에 정보로서 이용 가치가 있습니다.
마지막으로 매칭은 어떻게 할까요?
... 무식하게 모든 조합에 대해 특징점과 그 descriptor를 비교하면 됩니다.