Segmentation
영상을 잘게 구역화(분할)하는 방법을 알아봅니다.읽는데 10분 정도 걸려요.Thresholding
에너지 레벨을 thresholding 하는 방식으로 segmentation하는 기법입니다.
영역별로 threshold를 다르게 적용하는 방식도 있지만, 이번엔 전체적으로 같은 threshold 기준을 적용하는 방법을 알아볼 예정입니다.
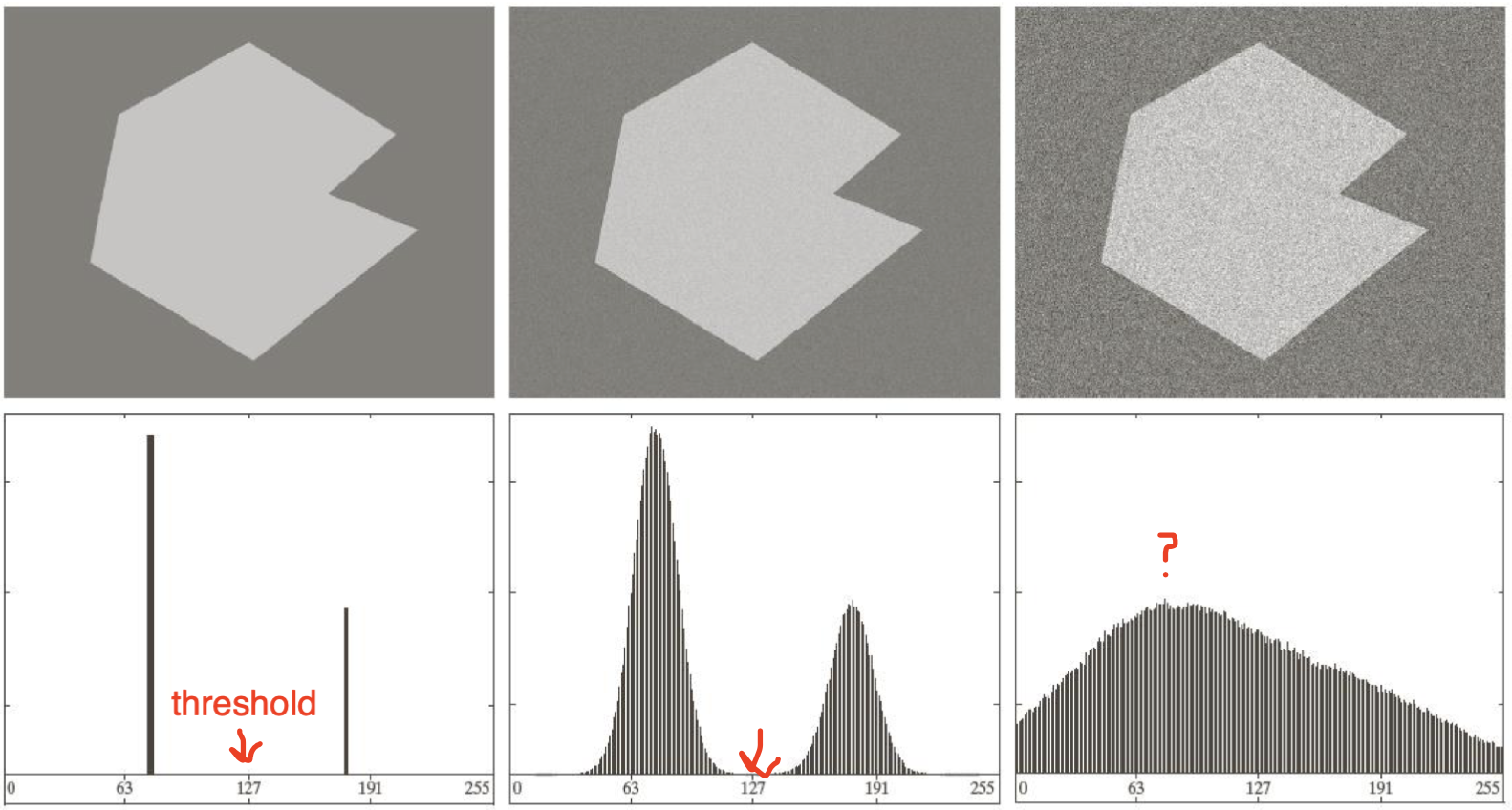
영상의 에너지레벨들을 을 잘 분할할 수 있는 에너지레벨을 기준으로 threshold를 하면 segmentation이 가능합니다.
그 방법은 아래와 같은 순서로 진행됩니다.
- 임의로 분할할 에너지레벨 T를 잡음.
- T를 기준으로 두 영역을 나눔 (between-class variance 관점).
- 각 영역의 평균을 계산함.
- 평균의 가운데 값으로 T를 이동.
- 2~4의 과정을 반복해 T가 특정 위치로 수렴하게 함.
위 방식을 거치면 단순한 영상에 대한 경우에는 segmentation이 가능합니다.
하지만, 약간의 노이즈가 끼거나 그림자가 지는 경우에는 정확하게 segmentation할 수 없을 뿐더러,
단순한 영상이라 하더라도, 초기에 T를 잘 못 설정하면 동작하지 않는다는 한계가 있습니다.
이를 해결하기 위한 몇 가지 방법들을 소개합니다.
Otsu's Method
between-class variance 관점에서는 가장 최적해를 도출해주는 방식으로 알려져있으며, 수식은 다음과 같습니다.
는 영상 전체의 평균이고, 는 threshold에 대한 class i에 대한 평균입니다 (위의 3번에 해당).
는 threshold에 대한 class i의 확률로서, 위 식은 에러를 계산할 때 크기를 반영해서 계산한다는 의미입니다.

즉, 영상에서 threshold할 때 큰 객체 뿐만 아니라, 작은 객체역시 threshold 가능합니다.
Smoothing
노이즈가 있는 영상에 대한 thresholding을 해야할 때 적용해볼 수 있는 방법입니다.
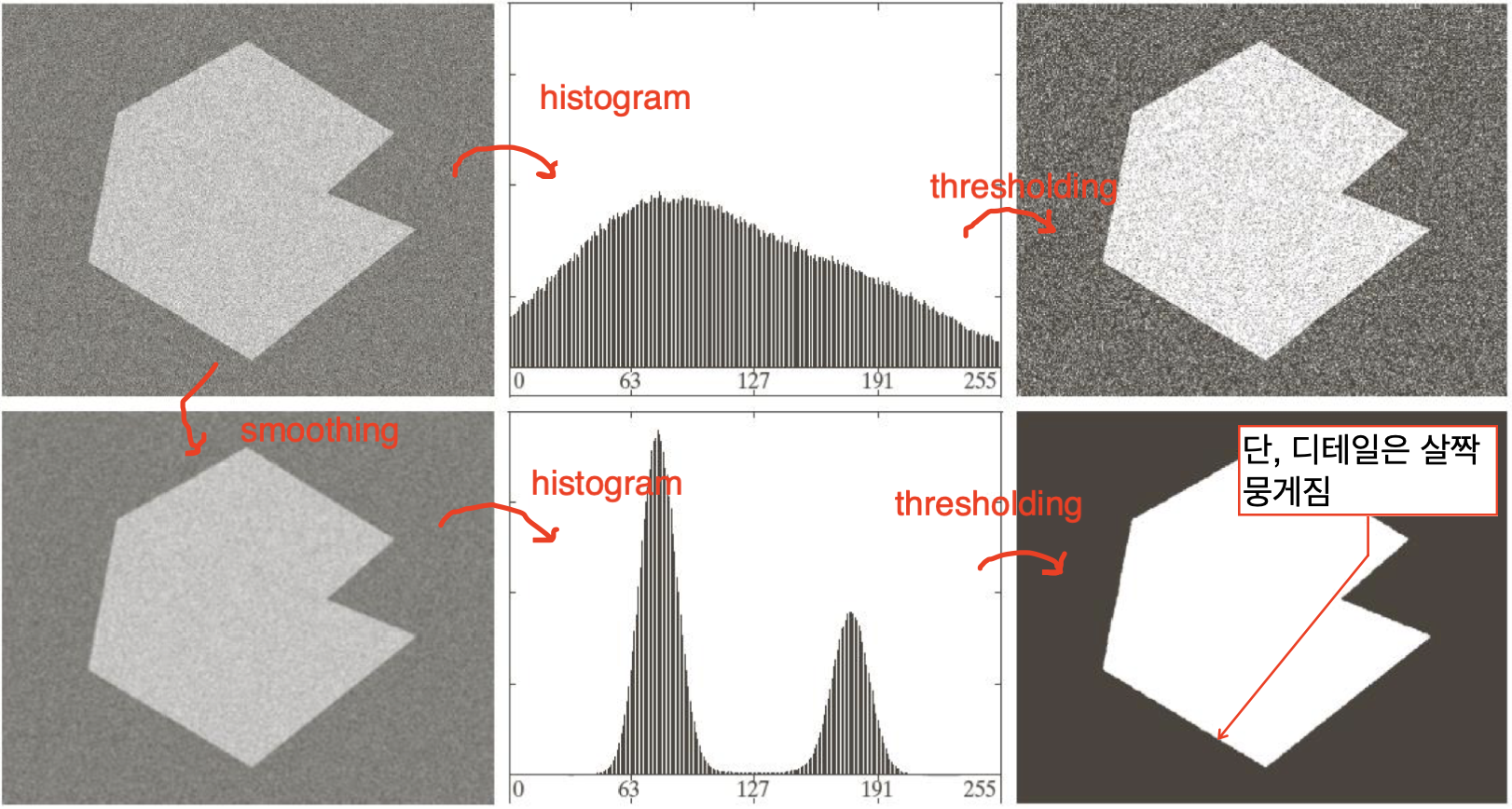
smoothing을 적용하면 threshold가 가능한 수준으로 히스토그램이 변할 수 있습니다.
하지만, 디테일은 약간 뭉게진다는 한계는 있습니다.
Edge
노이즈도 있고, 매우 작은 영역을 검출해야 하는 경우에는 위의 두 방식 역시 제대로 동작하지 않을 수 있습니다.
그럴 때 시도할 수 있는 방법으로 edge를 이용해서 시도하는 방법입니다.
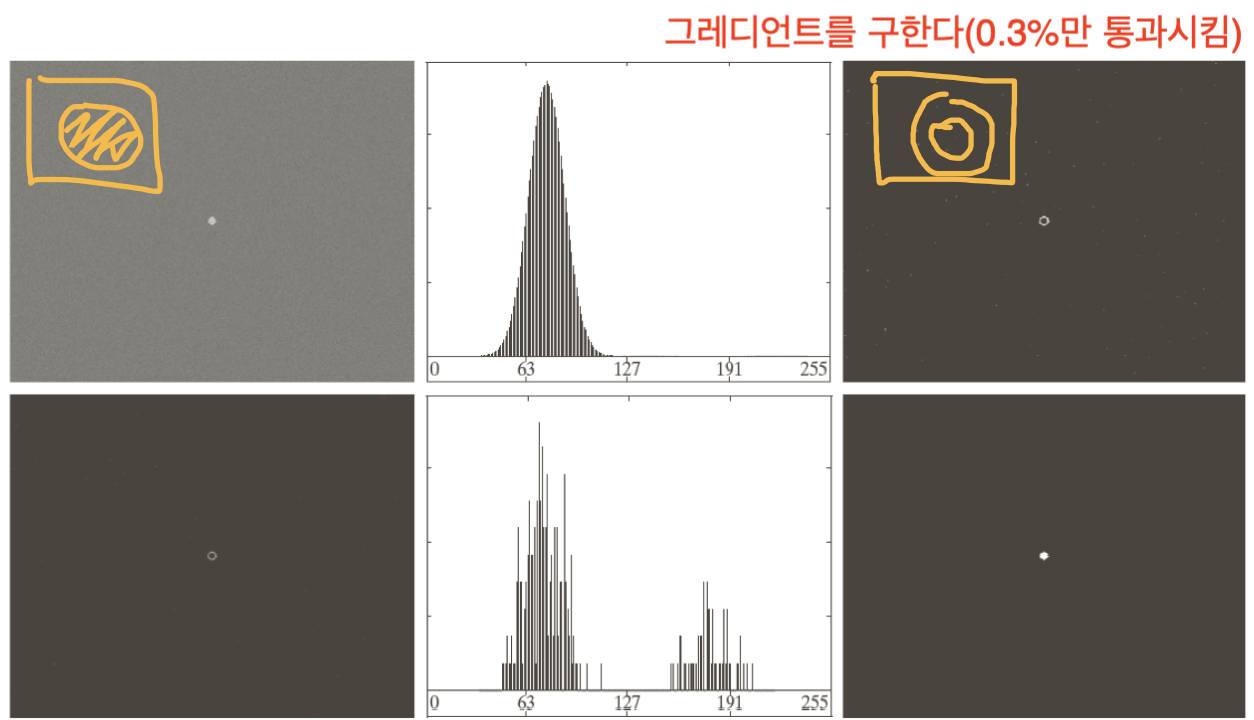
노이즈가 있는 영상에 대해 gradient를 구하고, threshold(99.7%)를 하여 우상단의 영상을 얻습니다.
이후 원본과 곱연산을 하여 좌하단의 영상을 구하고, 해당 영상에 대해 threshold를 하면 segmentation이 가능합니다.
지금부터 알아보는 내용에는 정형화된 방식이 없습니다.
상황에 맞는 방식을 사용하는 것이 좋습니다.
예로 들어, 노이즈가 많다? → smoothing을 해볼까?
세밀한 특징을 찾아야 한다? → edge를 구해볼까? 하는 식으로 말이죠.
K-means clustering
K-means 군집화 방법은 빅데이터, 인공지능 자료에서도 언급한 바가 있으니, 이론적인 내용은 생략하고, 바로 영상에 적용하는 방법에 대해 알아보겠습니다.
- 영상을 feature space로 변형한다.
- feature space 상에서 k-means clustering을 수행한다.
- 군집화 결과를 본래 영상공간으로 변형한다.
즉, feature space를 어떻게 설계하느냐에 따라 segmentation 되는 방식이 달라지게 됩니다.
우선 간단한 예시로 intensity(에너지 레벨)를 feature space로 사용해 봅시다.

만약, feature space를 RGB값으로 사용한다면? 위와 다른 결과가 나올 것입니다.
하지만, 색상, 에너지레벨만을 이용하는 feature space를 사용하는 경우 문제가 있습니다.
바로, 물리적인 공간이 떨어진 곳도 같은 cluster(segmentation)으로 분류가 된다는 점입니다.
이를 해결하려먼 feature space를 만들 때 intensity + position(x, y)도 함께 묶어 만들어주면, 위치가 크게 떨어져 있으면 다른 cluster로 묶이게 만들 수 있습니다.

그럼에도 불구하고, 위 방식 만으로는 위의 영상을 segmentation 할 수는 없을 것입니다. (사람이 하라해도 힘들 듯...)
이를 개선하기 위해 질감(texture)을 사용하여 feature space를 구성하는 방식을 사용해볼 수 있을 것입니다.
질감(texture)?
일종의 패턴으로, 특정 모양의 필터는 특정 모양의 패턴에만 반응하는 것을 이용합니다.
즉, 필터에 대한 반응성의 정도를 질감이라고 생각하면 될 거 같습니다.

예로 들어 위의 24종의 필터에 대한 반응도를 이용해 feature space를 만든다면, feature space는 24차원으로 구성될 것이며, 비슷한 질감인 부분은 비슷한 feature space 영역에 위치하게 되고,
결국, 비슷한 질감은 같은 cluseter로 군집화 될 것입니다.
k-means 방식은 간단하며, 빠르게 계산할 수 있고, feature space를 잘만 설계한다면 아주 잘 동작한 알고리즘처럼 보이지만, k-means 방법 역시 한계가 존재합니다.
-
k를 얼마로 설정해야 하는지 모른다.
-
초기값에 민감함.
-
outlier에 민감함.
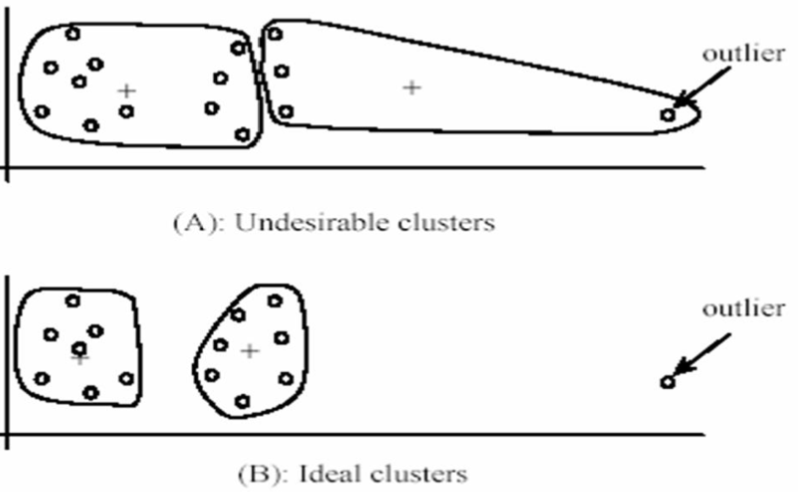
-
클러스터를 원형으로만 생성할 수 있음.
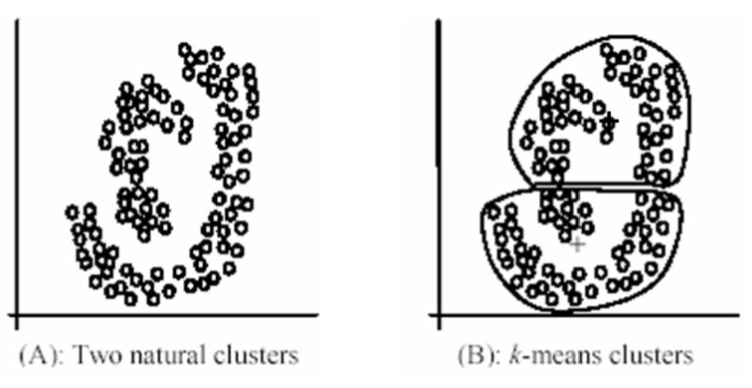
-
평균을 계산할 수 있다는 전제가 필요함.
Mean shift clustering
이 방식은 Mean shift algorithm을 이용하여 clustering 하는 방법으로, mean shift algorithm은 feature space에서 밀집도가 높은 부분을 찾는 알고리즘 입니다.
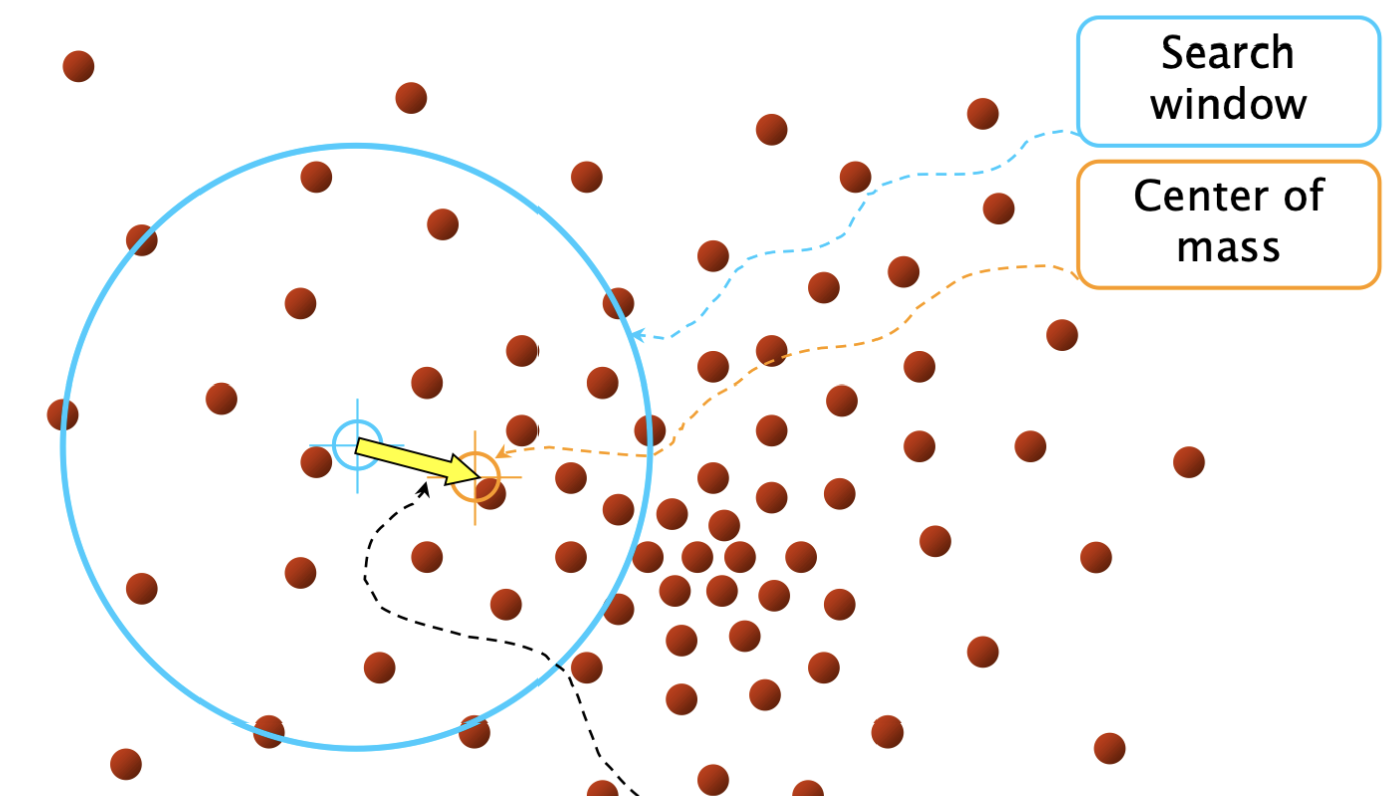
- 초기점을 하나 랜덤으로 설정하고, 탐색 윈도우 W의 크기를 적절히 세팅한다.
- W의 무게중심을 계산한다.
- W를 무게중심으로 이동시킨다.
- W가 움직이지 않을 때까지 반복한다.
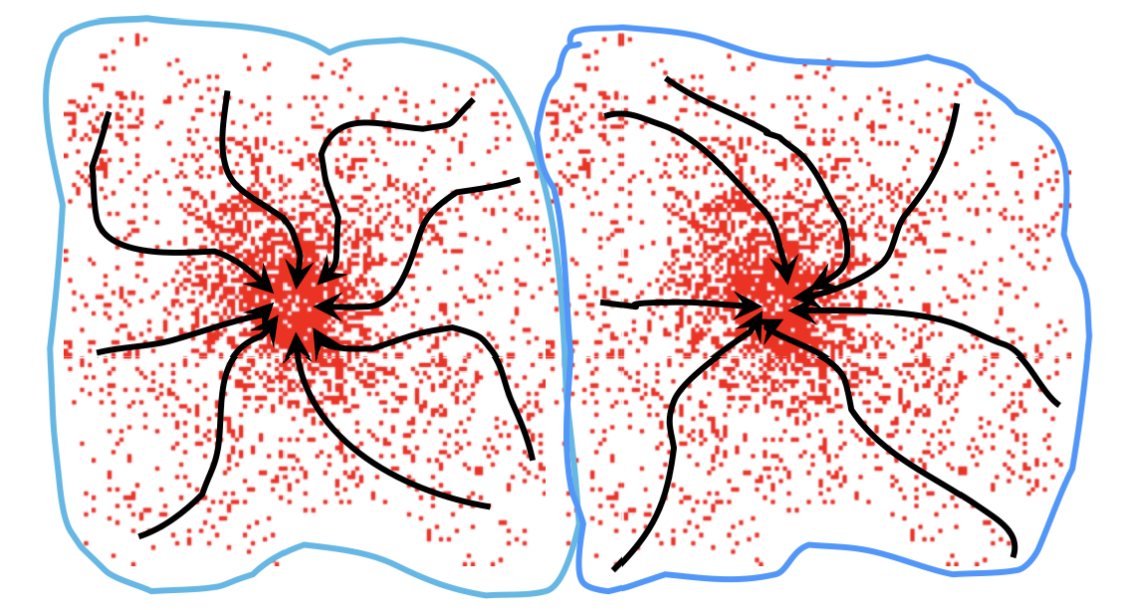
간단하게 이해해보자면, 각 feature space의 점들이 밀집도가 높아지는 방향으로 흘러가고, 한 점에서 모이는 점들은 같은 cluster로 분류됩니다.
이러한 특성 때문에 k-means의 한계를 극복할 수 있습니다.

정리하면, k-means는 거리 중심으로 segmentation 했는 반변,
mean shift는 무게 중심이 어디로 이동하지는지를 중심으로 segmentation 을 수행합니다.
mean shift 방식은 아래와 같은 장점이 있습니다.
- 일반적으로 여러 분야에서 사용 가능.
- 모델*이 필요없다. 즉, 어떠한 형태도 잘 클러스터링이 된다.
*모델: 얼굴을 잘 감지하는 모델, 타원을 잘 감지하는 모델 등등... - 파라미터가 1개(W 크기)밖에 없기에 단순하며, 그 1개 마저도 정하기 쉽다.
- outlier에 대해서도 잘 동작한다.
물론 W 크기에 종속적으로 동작한다는 단점이 있습니다.