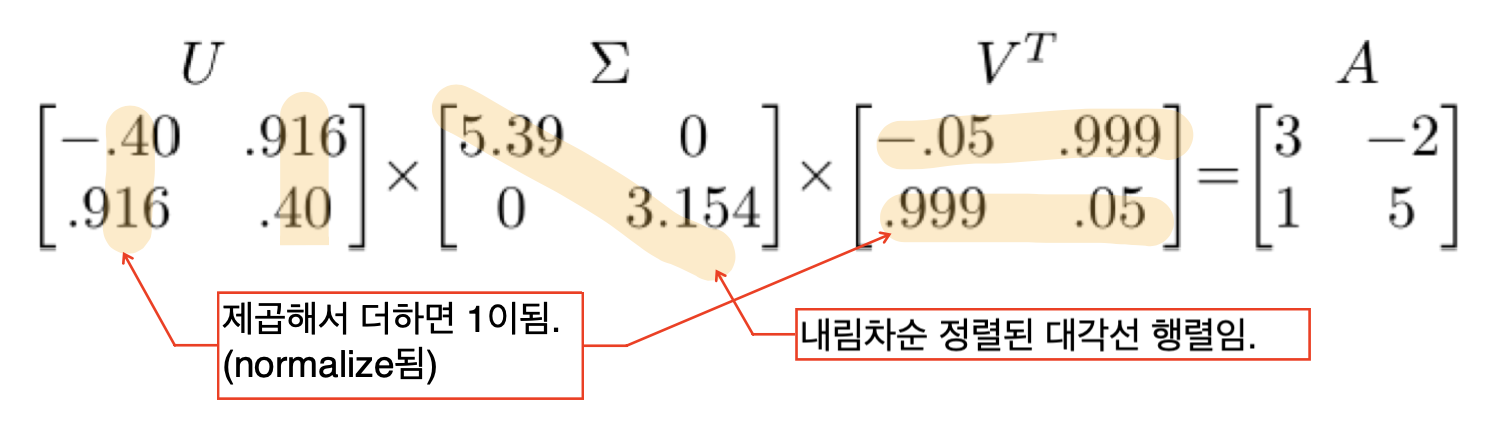
근데 이걸 왜 했느냐?
A를 6픽셀의 영상이라고 했을 때, A를 2개의 영상으로 분해한 꼴이다.
이 때, 에너지 레벨이 큰 영상부터 작은 영상 순서대로 분해한 것인데, 에너지 레벨이 크다는 것은 가장 두드러지는 특징을 의미한다.
즉, 사람 얼굴을 예로 들면, 위의 partial 영상부터 타원모양, 눈코입 위치, 피부 질감과 같이 큰 특징 순으로 얼굴영상을 분해한 것이다.
위 예시는 2개의 특징으로밖에 분리를 못하였지만, 아래의 예시를 살펴보자.
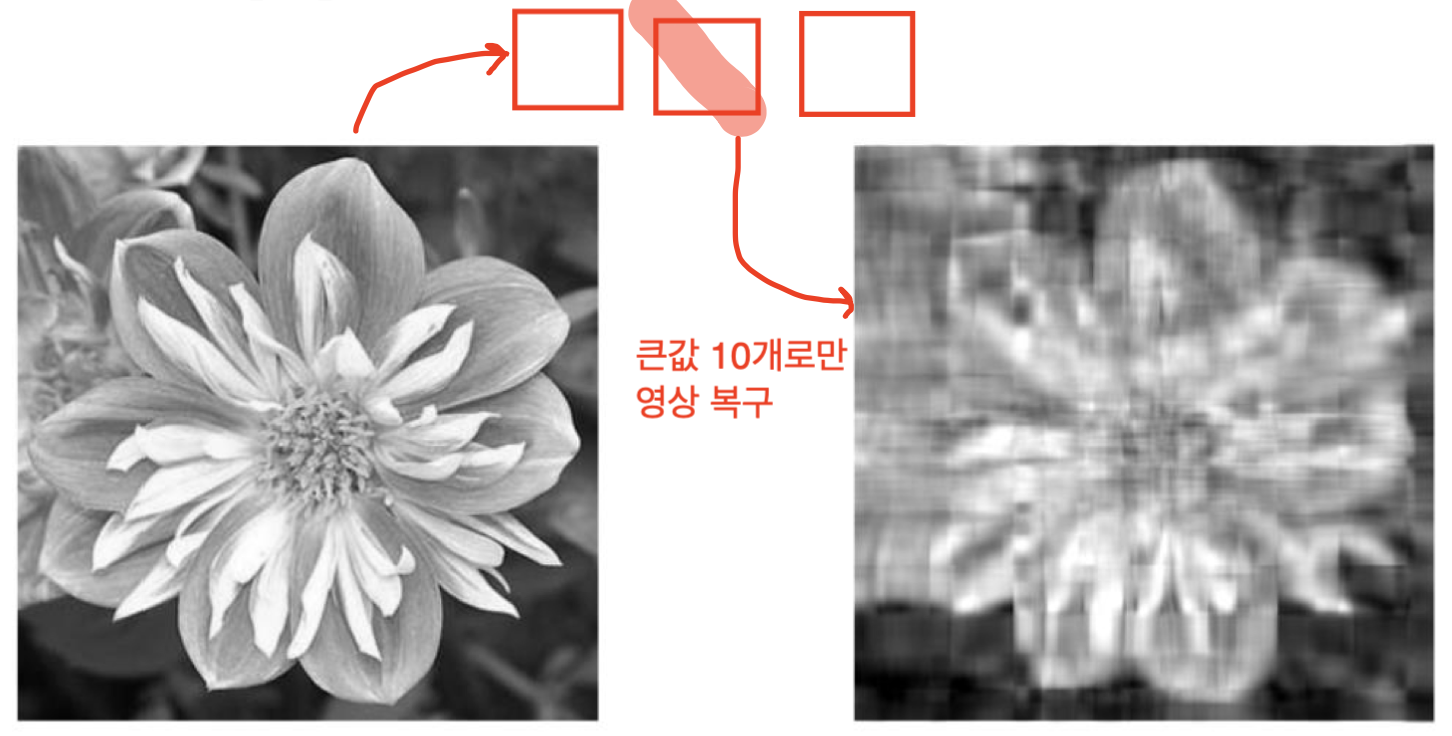
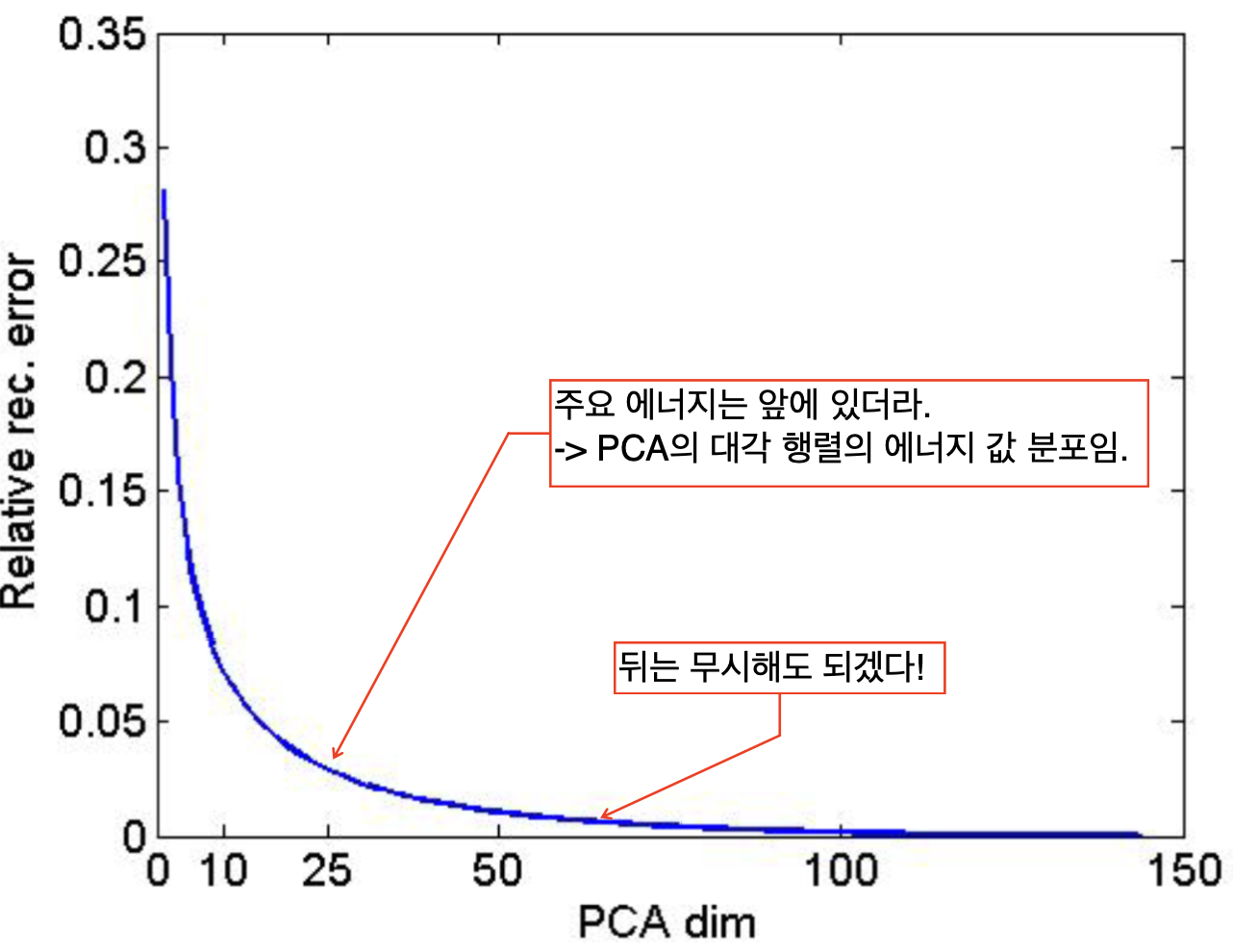
특징을 300개를 추출했는데, 그 중 상위 10개의 특징들로만 영상을 재구성하였다.
단, 3%만의 특징으로만 영상을 복원했는데, 상당히 원본을 닮을 수 있는 이유는 아래에서 알아보자.
PCA
Principal Component Analysis는 주성분 분석이라고 하는데, 이를 이용하면 고차원 데이터를 저차원 데이터로 차원 축소를 시킬 수 있다.
그런데 그 과정에서 데이터의 손실이 최소화 되도록 하는데, 어떤식으로 최소화 하는지 알아보자.
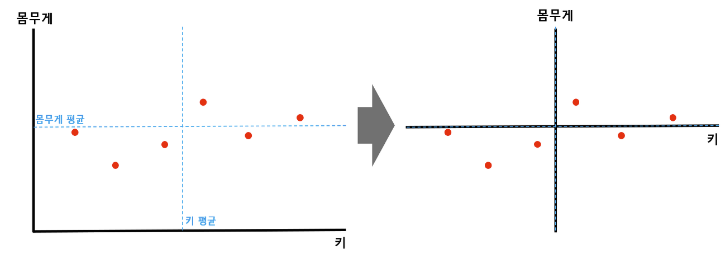
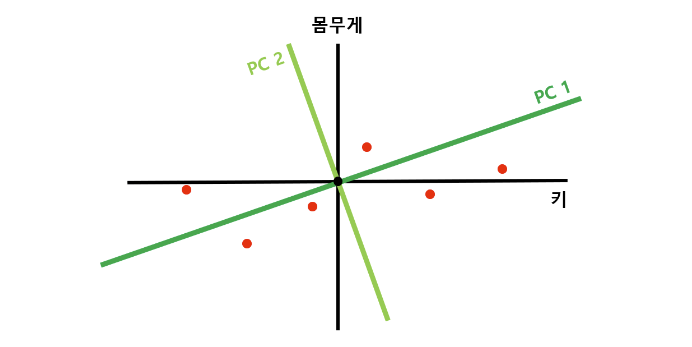
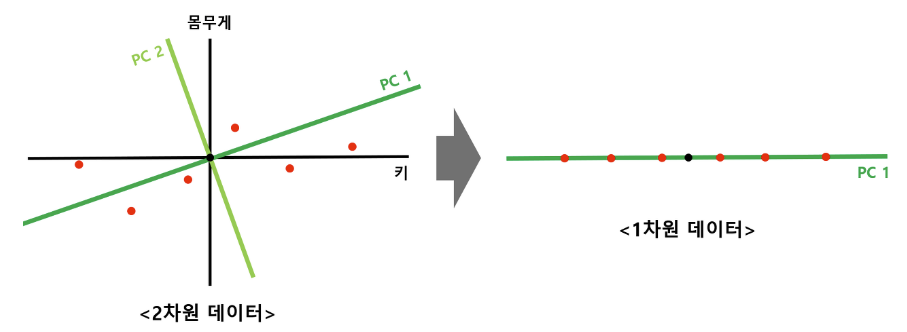
키, 몸무게로 표현된 2차원 데이터가 있다.
이 데이터를 1차원으로 잘 낮춰보기 위해 PCA를 사용하자.
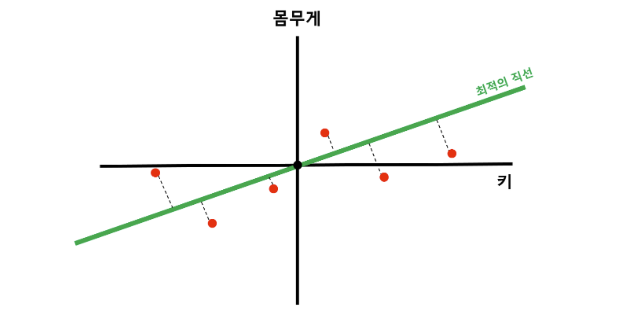
특정 직선에 수선의 발을 내렸을 때, 평균으로부터 수선의 발 까지의 길이의 제곱의 합이 최대가 되도록 하는 최적의 직선을 찾는다.
그리고, 그 최적의 직선에 수직인 다른 직선을 긋는다.
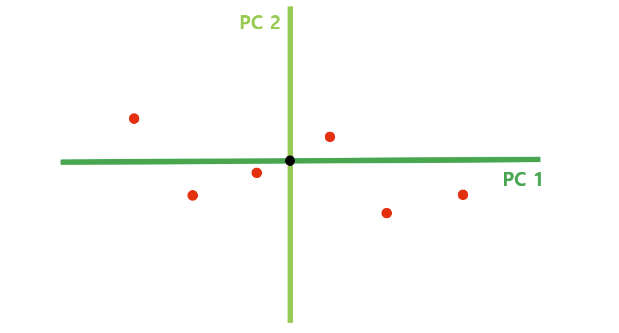
각 PC축이 전체 데이터를 얼마나 잘 표현하고 있는지 분석하기 위해 회전한다.
여기서 이 회전은 SVD의 U 행렬변환에 해당한다.
그리고 각 축이 데이터를 얼마나 잘 표현하는지에 대한 척도로 평균과 수선의 발까지의 거리의 제곱의 합으로 분석한다.
여기서 분석 결과가 SVD의 ∑ 행렬에 해당한다.
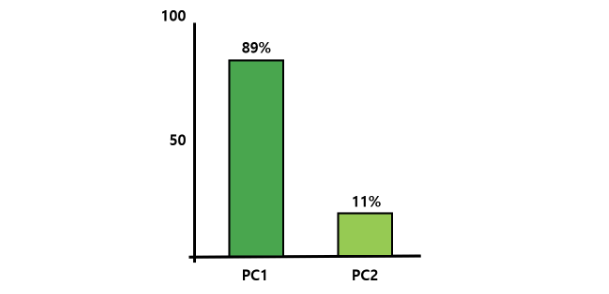
만약 PC1이 PC2 보다 압도적으로 전체 데이터를 잘 표현한다면?
PC1 만으로도 전체 데이터를 표현해도 크게 상관 없을 것이다.
따라서 PC2를 사용하지 않음으로써 차원을 낮출 수 있다.
대부분의 주요 특징은 높은 에너지 레벨을 보이고, 사소하고 디테일한 특징은 낮은 에너지 레벨을 보이기 때문에,
SVD에서 상위 몇개의 특징만으로 원본 영상을 비슷하게 재현할 수 있는 것이다.
Face Recognition
이제 기본 배경 지식을 어느정도 알았으니, 얼굴 인식하는 방식에 대해 알아보자.
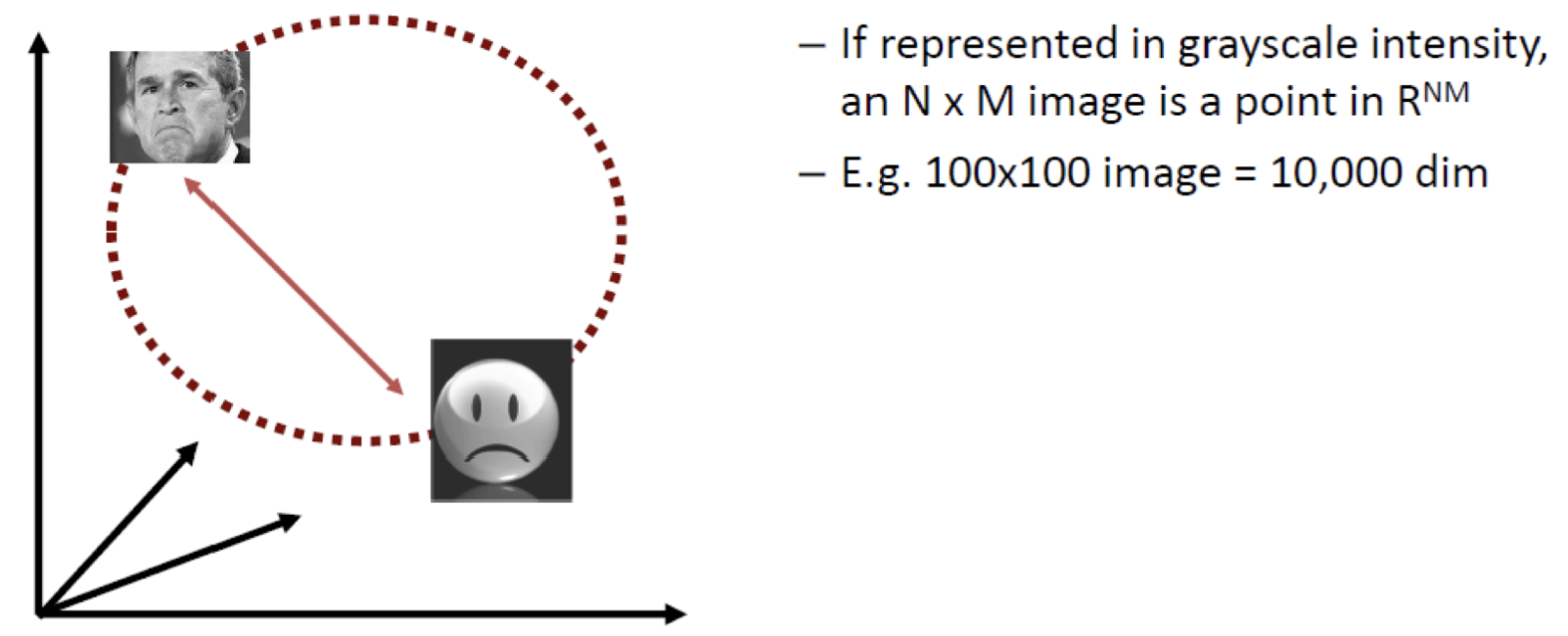
100x100 pixel의 얼굴 영상은 1만 차원의 하나의 포인트로 대응된다.
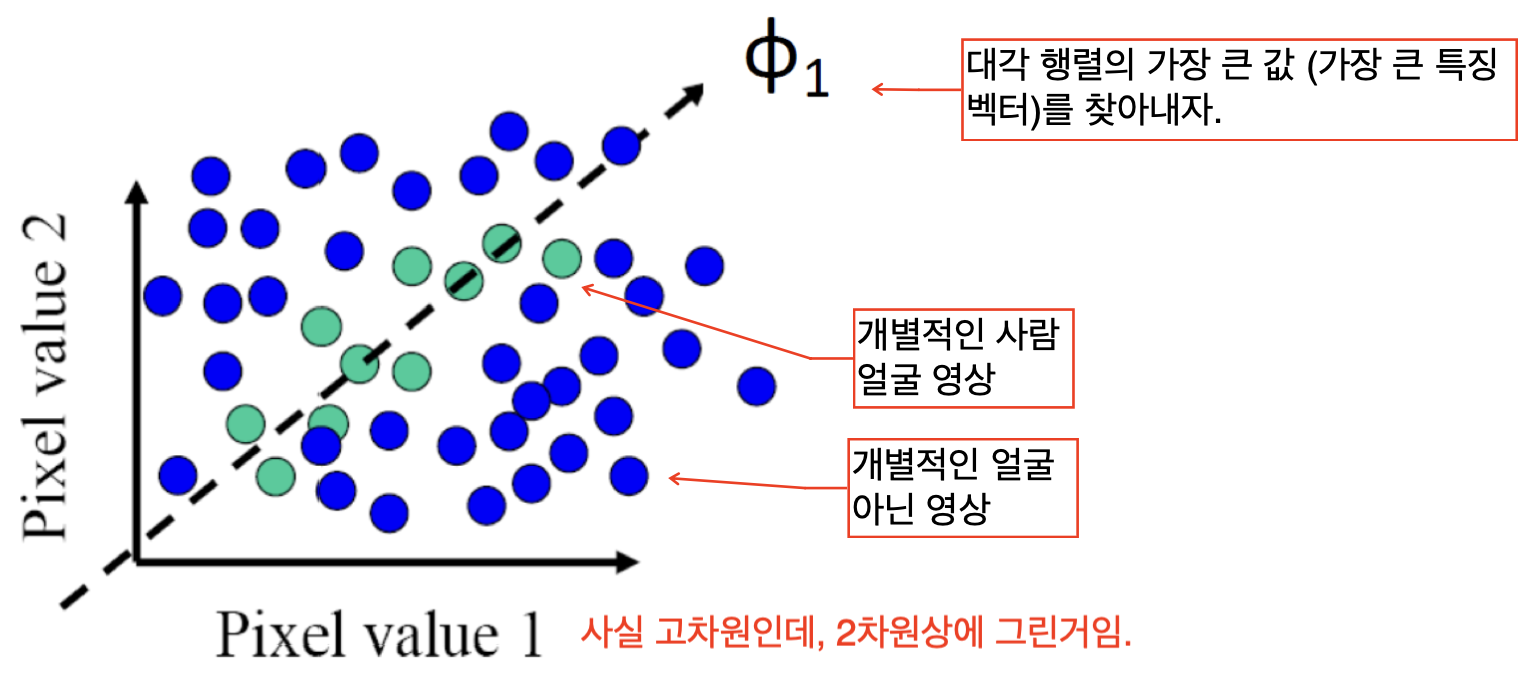
즉, 1만개의 특징 중, 얼굴을 표현하는 상위의 특징들로 차원을 축소한다면?
얼굴인 영상만을 인식할 수 있을 것이다.
따라서 PCA를 이용해서 얼굴의 가장 큰 특징벡터(sub-space)를 찾는 방식으로 얼굴 인식을 할 수 있으며,
sub-space는 학습 데이터를 학습을 시켜 얼굴의 eigenvector 들을 구하는 방식으로 진행된다.
얼굴의 특징을 나타내는 eigenvector를 구했다면, 이를 이용해서 여러 얼굴을 만들수도 있다.
이러한 여러 얼굴은 아래의 공식으로 표현할 수 있다.
xi≈μ+a1ϕ1+a2ϕ2+...+akϕk
여기서 중요한 점은 특징을 1만개를 사용하여 얼굴을 만든 것이 아니라, k개 만을 가지고 만들었다는 점이다.
즉, 1만 차원의 얼굴 영상을 단 k차원으로 줄여서 파악할 수 있다.